Getting Started with HSSM¶
HSSM is an open-source Python toolkit for Bayesian hierarchical sequential-sampling modeling. It helps researchers model choices and response times together to study latent decision and learning processes in cognitive (neuro)science. HSSM can be used to analyze behavioral (choice, rt), neural (EEG, fMRI) and other covariate (eye-tracking, SCR) data.
This tutorial is designed for new HSSM users. You will build a simple model from simulated data, learn how to inspect and validate it, and then extend the same workflow with priors, regressions, participant hierarchies, and model comparison.
What HSSM can help you model¶
HSSM is built for computational neurocognitive modeling. You can:
- fit sequential-sampling models to choices and response times;
- estimate trial-level, condition-level, neural, or behavioral effects on model parameters;
- pool information across participants with hierarchical models;
- use reinforcement-learning sequential-sampling models and alternative decision processes; and
- extend the model collection with custom likelihoods or low-level PyMC models.
What you will learn¶
- Build and inspect a DDM from simulated data.
- Diagnose posterior samples with ArviZ and compare them with known values.
- Check posterior predictions before interpreting a model.
- Add priors, regressions, and participant hierarchies.
- Compare models, then explore advanced customization when needed.
Prerequisites: basic Python and pandas familiarity are enough. No prior HSSM experience is assumed. If some Bayesian terms are new, you can still follow the workflow first and return to the explanations as they become useful.
A quick map of the workflow¶
Bayesian workflow map: data -> model -> posterior samples -> diagnostics -> posterior predictive checks -> model comparison -> interpretation.
The first part of this tutorial follows that loop with simulated data, where the true parameter values are known. Later sections reuse the same loop with richer models, regressions, participant-level effects, and comparison across candidate models.
What HSSM uses under the hood
- HSSM provides the user-facing model interface for sequential-sampling models.
- PyMC builds and samples the Bayesian model. Most calls to
.sample()use PyMC's MCMC samplers. - ArviZ summarizes, diagnoses, visualizes, and compares fitted Bayesian models.
- xarray and DataTree store labeled results such as posterior draws, sampler statistics, observed data, and posterior predictions.
- Bambi supplies the formula syntax used when HSSM parameters depend on predictors, such as
v ~ 1 + x. - PyTensor and JAX are computational backends. You usually only notice them when choosing advanced likelihoods or samplers.
- ssm-simulators generates synthetic sequential-sampling data for examples and simulation studies.
- ONNX is a portable format for neural-network likelihood approximators used by some advanced models.
You do not need to master these packages before starting. The main idea is to recognize which tool is responsible for each step of the workflow.
Run this tutorial¶
For Colab, run the installation cell below and restart the runtime once installation completes. A GPU can help for some approximate-likelihood models, but it is not required for the introductory workflow.
Locally, run the notebook from a dedicated environment and execute cells from top to bottom. The examples use short runs for teaching; rigorous analyses should use more draws, tuning, and chains.
# Run this in Colab
#!pip install git+https://github.com/lnccbrown/HSSM
Setup¶
import logging
import warnings
warnings.filterwarnings("ignore")
logging.getLogger("pytensor").setLevel(logging.ERROR)
import arviz as az
import bambi as bmb
import hddm_wfpt
import jax
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import hssm
random_seed_sim = 134
np.random.seed(random_seed_sim)
# PyMC supports a compact, single bar across chains. External JAX samplers
# accept a boolean and manage their own progress display.
PYMC_PROGRESS = "combined"
EXTERNAL_PROGRESS = True
def add_trace_reference_lines(plot_collection, values) -> None:
"""Mark true values on distribution and MCMC-trace panels."""
for name, value in values.items():
if name not in plot_collection.data.data_vars:
continue
plot_collection.get_target(name, {"column": "dist"}).axvline(
value, color="red", linestyle="--"
)
plot_collection.get_target(name, {"column": "trace"}).axhline(
value, color="red", linestyle="--"
)
1. Build and inspect your first HSSM model¶
Simulate a simple drift-diffusion dataset¶
The drift-diffusion model (DDM) is a useful first example because it describes both the response a participant makes and how long the decision takes. Its key parameters are:
v: drift rate, the average rate of evidence accumulation;a: boundary separation, a speed--accuracy setting;z: starting point, an a priori response bias; andt: non-decision time, such as encoding and motor time.
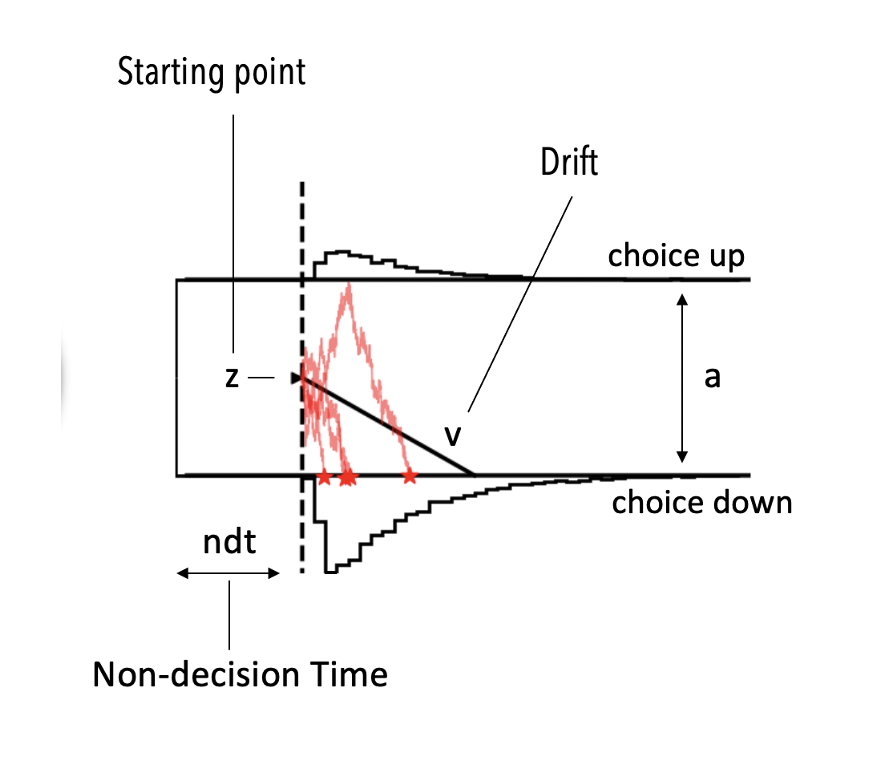
We simulate data with known values first. This makes the later posterior checks concrete: the red reference lines will show the values used to generate the data.
param_dict_init = dict(v=0.5, a=1.5, z=0.5, t=0.5)
v_true, a_true, z_true, t_true = (
param_dict_init["v"],
param_dict_init["a"],
param_dict_init["z"],
param_dict_init["t"],
)
dataset = hssm.simulate_data(
model="ddm",
theta=param_dict_init,
size=500,
)
dataset
| rt | response | |
|---|---|---|
| 0 | 3.320658 | 1.0 |
| 1 | 3.959118 | 1.0 |
| 2 | 1.194643 | -1.0 |
| 3 | 1.309059 | 1.0 |
| 4 | 2.604827 | 1.0 |
| ... | ... | ... |
| 495 | 3.186444 | 1.0 |
| 496 | 2.706113 | 1.0 |
| 497 | 1.235891 | -1.0 |
| 498 | 1.692380 | -1.0 |
| 499 | 9.763319 | -1.0 |
500 rows × 2 columns
Fit the model¶
To create the simplest HSSM model, provide a pandas.DataFrame with rt and response columns. HSSM supplies the default DDM configuration, including an analytical likelihood and default priors.
What happens in this one line: HSSM checks the data columns, chooses the default DDM parameterization, attaches priors and bounds, and builds the corresponding PyMC model. If you have used HDDM, the workflow will feel familiar. HSSM builds the probabilistic model with PyMC and uses Bambi-style formulas when parameters depend on predictors.
simple_ddm_model = hssm.HSSM(data=dataset)
Model initialized successfully.
simple_ddm_model
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 500
Parameters:
v:
Prior: Normal(mu: 0.0, sigma: 2.0)
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
The printed model summary is the first specification check. It shows the observations, free parameters, priors, bounds, and likelihood, so you can confirm that HSSM is estimating the model you intended before spending time sampling.
Inspect the model graph¶
simple_ddm_model.graph()

The graph uses probabilistic-programming notation:
- white nodes are unknown random variables to estimate;
- the grey node is the observed choice/response-time data;
- rounded rectangles describe dimensions; and
- sharp-cornered rectangles denote deterministic quantities.
For simple models the graph is compact. The goal is not to memorize every node, but to check that the observed data, parameters, and deterministic transformations match your scientific story. The graph becomes especially helpful once regressions and participant-level effects are added.
Sample from the posterior¶
We now use PyMC's NUTS sampler to draw posterior samples. A posterior sample is a collection of plausible parameter values after combining the prior, the likelihood, and the observed data. The settings below are intentionally small so the tutorial remains runnable; increase chains, draws, and tuning for a real analysis.
infer_data_simple_ddm_model = simple_ddm_model.sample(
sampler="pymc",
cores=1,
chains=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=True),
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 5 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
Sampling returns an xarray.DataTree: a labeled container for all the fitted-model results. Next, we will inspect its contents and use ArviZ to assess what the sampler returned.
type(infer_data_simple_ddm_model)
xarray.core.datatree.DataTree
Understand the fitted result¶
HSSM (via the ArviZ package) stores results in an xarray.DataTree. Each group contains a related part of the Bayesian workflow, such as posterior samples, pointwise log likelihoods, sampler statistics, or observed data.
You do not need to manipulate every group to use HSSM, but recognizing this structure makes it easier to use ArviZ and to add your own analyses. When you see later calls such as az.summary(...), az.plot_trace(...), or az.compare(...), ArviZ is reading these labeled groups.
infer_data_simple_ddm_model
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
│ Data variables:
│ v (chain, draw) float64 8kB 0.5076 0.5466 0.5739 ... 0.5026 0.4553
│ t (chain, draw) float64 8kB 0.4856 0.5058 0.4758 ... 0.534 0.5085
│ a (chain, draw) float64 8kB 1.47 1.417 1.48 ... 1.408 1.406 1.428
│ z (chain, draw) float64 8kB 0.4975 0.4523 0.4755 ... 0.4736 0.4973
│ Attributes:
│ created_at: 2026-07-10T15:47:47.593941+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 5.076463937759399
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
│ Data variables: (12/18)
│ diverging (chain, draw) bool 1kB False False ... False False
│ n_steps (chain, draw) float64 8kB 7.0 7.0 7.0 ... 1.0 7.0 7.0
│ energy (chain, draw) float64 8kB 1.034e+03 ... 1.034e+03
│ smallest_eigval (chain, draw) float64 8kB nan nan nan ... nan nan nan
│ tree_depth (chain, draw) int64 8kB 3 3 3 2 3 2 3 ... 3 3 3 1 3 3
│ process_time_diff (chain, draw) float64 8kB 0.002175 ... 0.001986
│ ... ...
│ step_size_bar (chain, draw) float64 8kB 0.6084 0.6084 ... 0.6483
│ reached_max_treedepth (chain, draw) bool 1kB False False ... False False
│ energy_error (chain, draw) float64 8kB 0.2016 0.1403 ... -0.08032
│ perf_counter_start (chain, draw) float64 8kB 7.902e+04 ... 7.903e+04
│ perf_counter_diff (chain, draw) float64 8kB 0.002075 ... 0.001926
│ step_size (chain, draw) float64 8kB 0.7384 0.7384 ... 0.953
│ Attributes:
│ created_at: 2026-07-10T15:47:47.605353+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 5.076463937759399
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /observed_data
│ Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2)
│ Coordinates:
│ * __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499
│ * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1
│ Data variables:
│ rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 3...
│ Attributes:
│ created_at: 2026-07-10T15:47:47.608970+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: []
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
└── Group: /log_likelihood
Dimensions: (chain: 2, draw: 500, __obs__: 500)
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499
* __obs__ (__obs__) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499
Data variables:
rt,response (chain, draw, __obs__) float64 4MB -2.273 -2.706 ... -5.888
Attributes:
modeling_interface: bambi
modeling_interface_version: 0.18.0For this model, the most important groups are:
posterior: sampled values for model parameters such asv,a,z, andt;sample_stats: sampler diagnostics such as divergences, tree depth, and acceptance information;observed_data: the choices and response times that were modeled;log_likelihood: trial-level likelihood contributions, needed for many comparison methods; andposterior_predictive: simulated data from the fitted model, added later when we run posterior predictive checks.
Work with posterior draws¶
Access groups and variables¶
infer_data_simple_ddm_model.posterior
<xarray.DataTree 'posterior'>
Group: /posterior
Dimensions: (chain: 2, draw: 500)
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
v (chain, draw) float64 8kB 0.5076 0.5466 0.5739 ... 0.5026 0.4553
t (chain, draw) float64 8kB 0.4856 0.5058 0.4758 ... 0.534 0.5085
a (chain, draw) float64 8kB 1.47 1.417 1.48 ... 1.408 1.406 1.428
z (chain, draw) float64 8kB 0.4975 0.4523 0.4755 ... 0.4736 0.4973
Attributes:
created_at: 2026-07-10T15:47:47.593941+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.1.0
sample_dims: ['chain', 'draw']
sampling_time: 5.076463937759399
tuning_steps: 500
modeling_interface: bambi
modeling_interface_version: 0.18.0infer_data_simple_ddm_model.posterior.a.head()
<xarray.DataArray 'a' (chain: 2, draw: 5)> Size: 80B
array([[1.47008571, 1.41726544, 1.48014251, 1.45100462, 1.42185977],
[1.45282672, 1.45033339, 1.41147757, 1.46758121, 1.50906409]])
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 40B 0 1 2 3 4To simply access the underlying data as a numpy.ndarray, we can use .values (as e.g. when using pandas.DataFrame objects).
type(infer_data_simple_ddm_model.posterior.a.values)
numpy.ndarray
Combine chains and draws¶
Many follow-up calculations are easier when the chain and draw dimensions are combined into a single sample dimension. ArviZ's extract helper provides a convenient interface for this common operation. The following cell shows the equivalent lower-level xarray operation.
idata_extracted = az.extract(infer_data_simple_ddm_model)
idata_extracted
<xarray.Dataset> Size: 56kB
Dimensions: (sample: 1000)
Coordinates:
* sample (sample) object 8kB MultiIndex
* chain (sample) int64 8kB 0 0 0 0 0 0 0 0 0 0 0 ... 1 1 1 1 1 1 1 1 1 1 1
* draw (sample) int64 8kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
v (sample) float64 8kB 0.5076 0.5466 0.5739 ... 0.4367 0.5026 0.4553
t (sample) float64 8kB 0.4856 0.5058 0.4758 ... 0.517 0.534 0.5085
a (sample) float64 8kB 1.47 1.417 1.48 1.451 ... 1.408 1.406 1.428
z (sample) float64 8kB 0.4975 0.4523 0.4755 ... 0.4921 0.4736 0.4973
Attributes:
created_at: 2026-07-10T15:47:47.593941+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.1.0
sample_dims: ['sample']
sampling_time: 5.076463937759399
tuning_steps: 500
modeling_interface: bambi
modeling_interface_version: 0.18.0infer_data_simple_ddm_model.posterior.ds.stack(sample=("chain", "draw"))
<xarray.Dataset> Size: 56kB
Dimensions: (sample: 1000)
Coordinates:
* sample (sample) object 8kB MultiIndex
* chain (sample) int64 8kB 0 0 0 0 0 0 0 0 0 0 0 ... 1 1 1 1 1 1 1 1 1 1 1
* draw (sample) int64 8kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
v (sample) float64 8kB 0.5076 0.5466 0.5739 ... 0.4367 0.5026 0.4553
t (sample) float64 8kB 0.4856 0.5058 0.4758 ... 0.517 0.534 0.5085
a (sample) float64 8kB 1.47 1.417 1.48 1.451 ... 1.408 1.406 1.428
z (sample) float64 8kB 0.4975 0.4523 0.4755 ... 0.4921 0.4736 0.4973
Attributes:
created_at: 2026-07-10T15:47:47.593941+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.1.0
sample_dims: ['chain', 'draw']
sampling_time: 5.076463937759399
tuning_steps: 500
modeling_interface: bambi
modeling_interface_version: 0.18.0ArviZ for diagnostics and visualization¶

HSSM returns xarray-based inference results that work directly with ArviZ. We will use ArviZ to summarize posterior uncertainty, inspect MCMC traces, check posterior predictions, and compare models. The examples below focus on the few summaries and plots that are most useful when starting out.
Diagnose and interpret the posterior¶
az.summary(
infer_data_simple_ddm_model,
var_names=[var_name.name for var_name in simple_ddm_model.pymc_model.free_RVs],
)
| mean | sd | eti89_lb | eti89_ub | ess_bulk | ess_tail | r_hat | mcse_mean | mcse_sd | |
|---|---|---|---|---|---|---|---|---|---|
| t | 0.51 | 0.029 | 0.46 | 0.56 | 529 | 591 | 1.00 | 0.0013 | 0.00086 |
| a | 1.426 | 0.04 | 1.4 | 1.5 | 575 | 678 | 1.01 | 0.0017 | 0.0012 |
| z | 0.486 | 0.017 | 0.46 | 0.51 | 529 | 661 | 1.00 | 0.00074 | 0.0005 |
| v | 0.507 | 0.045 | 0.43 | 0.58 | 659 | 648 | 1.00 | 0.0018 | 0.0012 |
The summary reports posterior location and uncertainty for each parameter, plus diagnostics. The mean and sd columns describe the center and spread of the posterior draws. The highest-density interval (hdi_3% to hdi_97% by default) gives a compact uncertainty interval. Start diagnostics with r_hat: values near 1 indicate that independent chains explored the same distribution. As a practical rule, investigate values above 1.01 and inspect trace plots before interpreting parameter estimates.
Trace and distribution plots¶
pc = az.plot_trace_dist(infer_data_simple_ddm_model)
add_trace_reference_lines(pc, param_dict_init)

HSSM also stores the latest result on .traces. Both access patterns are equivalent here; using .traces is convenient when working with a fitted HSSM object.
pc = az.plot_trace_dist(simple_ddm_model.traces)
add_trace_reference_lines(pc, param_dict_init)
The distribution panel summarizes posterior uncertainty for each parameter. The MCMC trace panel shows each chain across draws; stable, overlapping chains suggest the sampler is repeatedly visiting the same high-probability region rather than getting stuck in different places. The red reference lines mark the known values used to simulate the data.
Forest plots¶
az.plot_forest(simple_ddm_model.traces)
<arviz_plots.plot_collection.PlotCollection at 0x12de9b6e0>

A forest plot turns posterior uncertainty into intervals, which is useful when many parameters or chains are shown at once. By default, chains are shown separately. Combining chains can make a large forest plot easier to scan once you have already checked trace diagnostics.
az.plot_forest(simple_ddm_model.traces, combined=True)
<arviz_plots.plot_collection.PlotCollection at 0x12e299820>

Marginal posterior plots¶
az.plot_dist(simple_ddm_model.traces, kind="hist")
<arviz_plots.plot_collection.PlotCollection at 0x12e29a8d0>

A marginal posterior plot ignores sampling order and focuses on the distribution of one parameter at a time. Because this is simulated data, we can compare the posterior with the known generating values. The standalone marginal plot below uses vertical reference lines; the paired trace/distribution plots use vertical lines on distributions and horizontal lines on traces.
pc = az.plot_dist(simple_ddm_model.traces, kind="hist")
az.add_lines(
pc,
values=param_dict_init,
orientation="vertical",
visuals={"ref_line": dict(color="red", linestyle="--")},
)
<arviz_plots.plot_collection.PlotCollection at 0x12e3be690>

Posterior pair plots¶
Pair plots reveal relationships between posterior parameters. Strong trade-offs can signal weak identification: when one parameter increases, another may compensate while producing similar predicted behavior. This is common in cognitive models, where several parameters can affect the same response-time or choice pattern.
az.plot_pair(simple_ddm_model.traces, marginal_kind="kde")
<arviz_plots.plot_matrix.PlotMatrix at 0x12dee6cf0>

ArviZ provides many additional diagnostics and plotting tools. The current user guide is the best next reference when you need a specific plot or diagnostic.
Compute quantities from posterior draws¶
# Calculate the correlation matrix
posterior_correlation_matrix = np.corrcoef(
np.stack(
[idata_extracted[var_].values for var_ in idata_extracted.data_vars.variables]
)
)
num_vars = posterior_correlation_matrix.shape[0]
# Make heatmap
fig, ax = plt.subplots(1, 1)
cax = ax.imshow(posterior_correlation_matrix, cmap="coolwarm", vmin=-1, vmax=1)
fig.colorbar(cax, ax=ax)
ax.set_title("Posterior Correlation Matrix")
# Add ticks
ax.set_xticks(range(posterior_correlation_matrix.shape[0]))
ax.set_xticklabels([var_ for var_ in idata_extracted.data_vars.variables])
ax.set_yticks(range(posterior_correlation_matrix.shape[0]))
ax.set_yticklabels([var_ for var_ in idata_extracted.data_vars.variables])
# Annotate heatmap
for i in range(num_vars):
for j in range(num_vars):
ax.text(
j,
i,
f"{posterior_correlation_matrix[i, j]:.2f}",
ha="center",
va="center",
color="black",
)
plt.show()

Check posterior predictions¶
Good MCMC diagnostics show that the sampler explored the stated model reliably; they do not show that the model captures the data. Posterior predictive checks compare data simulated from the fitted model with the observations and are an essential step before substantive interpretation. In workflow terms, this is where we ask: if the fitted model were true, would it generate choices and response times that look like the data we actually observed?
simple_ddm_model.sample_posterior_predictive(draws=100)
dt=None, we use the traces assigned to the HSSM object as datatree.
simple_ddm_model.plot_predictive()
<Axes: title={'center': 'Posterior Predictive Distribution'}, xlabel='Response Time', ylabel='Density'>

The first posterior predictive call adds a posterior_predictive group to the fitted result, and plot_predictive() visualizes those simulated datasets against the observations. If predictions reproduce the main features of the observed response-time and choice distributions, the model is a useful approximation for those features. Systematic mismatches suggest revisiting the likelihood, parameterization, covariates, or model family.
2. Choose a model and likelihood¶
simple_ddm_model.loglik_kind
'analytical'
The DDM above used HSSM’s analytical likelihood. Other sequential-sampling models may instead use an approx_differentiable likelihood, such as a likelihood approximation network (LAN), or a user-supplied blackbox likelihood. The model interface stays similar; HSSM chooses compatible computational machinery behind the scenes.
An angle model with collapsing boundaries¶
The angle model extends the DDM with theta, which controls the rate at which decision boundaries collapse over time.
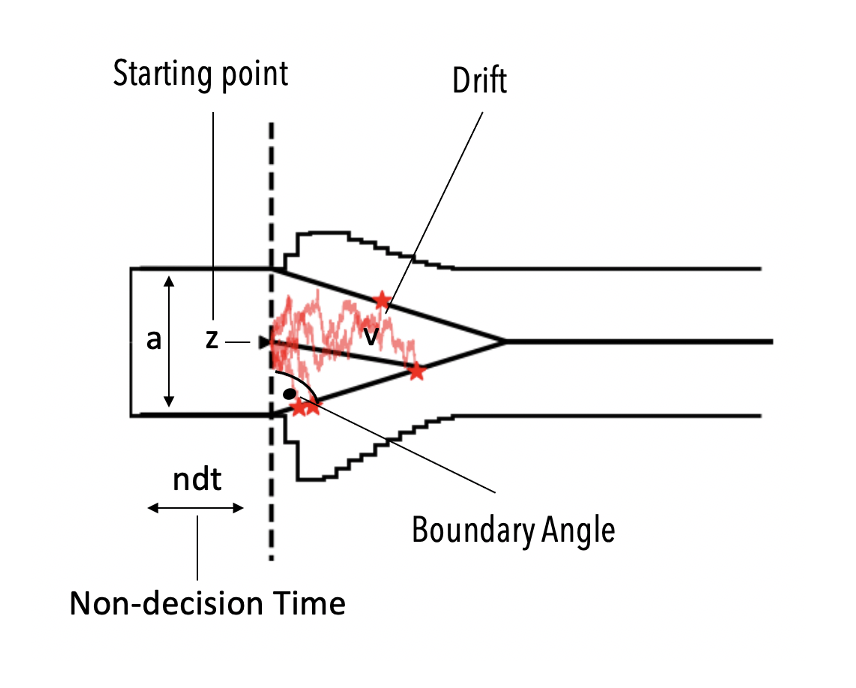
Collapsing boundaries are useful when urgency or time pressure may change a participant’s decision criterion. HSSM makes inference for these models practical through packaged approx_differentiable likelihoods.
# Simulate angle data
v_angle_true = 0.5
a_angle_true = 1.5
z_angle_true = 0.5
t_angle_true = 0.2
theta_angle_true = 0.2
param_dict_angle = dict(v=0.5, a=1.5, z=0.5, t=0.2, theta=0.2)
dataset_angle = hssm.simulate_data(model="angle", theta=param_dict_angle, size=1000)
We pass a single additional argument to our HSSM class and set model='angle'.
model_angle = hssm.HSSM(data=dataset_angle, model="angle")
model_angle
Model initialized successfully.
Hierarchical Sequential Sampling Model
Model: angle
Response variable: rt,response
Likelihood: approx_differentiable
Observations: 1000
Parameters:
v:
Prior: Uniform(lower: -3.0, upper: 3.0)
Explicit bounds: (-3.0, 3.0)
a:
Prior: Uniform(lower: 0.3, upper: 3.0)
Explicit bounds: (0.3, 3.0)
z:
Prior: Uniform(lower: 0.1, upper: 0.9)
Explicit bounds: (0.1, 0.9)
t:
Prior: Uniform(lower: 0.001, upper: 2.0)
Explicit bounds: (0.001, 2.0)
theta:
Prior: Uniform(lower: -0.1, upper: 1.3)
Explicit bounds: (-0.1, 1.3)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
The graph now includes the additional theta parameter. This is a quick way to confirm that the model specification matches the scientific question.
model_angle.graph()

Let's check the type of likelihood that is used under the hood ...
model_angle.loglik_kind
'approx_differentiable'
This model uses an approx_differentiable likelihood. In the packaged model collection, that typically means a LAN is used internally to approximate the likelihood.
jax.config.update("jax_enable_x64", False)
infer_data_angle = model_angle.sample(
sampler="numpyro",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
# mp_ctx="spawn",
progressbar=EXTERNAL_PROGRESS,
)
Using default initvals.
NUTS[numpyro]: [a, theta, t, z, v] sample: 100%|██████████| 1000/1000 [00:15<00:00, 63.73it/s, 11 steps of size 2.41e-01. acc. prob=0.91] sample: 100%|██████████| 1000/1000 [00:15<00:00, 63.02it/s, 15 steps of size 2.32e-01. acc. prob=0.94] We recommend running at least 4 chains for robust computation of convergence diagnostics The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
pc = az.plot_trace_dist(model_angle.traces)
add_trace_reference_lines(pc, param_dict_angle)

3. Customize priors and model structure¶
Priors express plausible parameter ranges before observing the data. HSSM supports defaults that respect model bounds, fixed values for parameters you do not want to estimate, and explicit PyMC distributions when you need stronger domain knowledge.
Fix parameters when the design justifies it¶
Sometimes a parameter is fixed by design or is outside the present research question. Here we estimate only the drift rate v while holding the other DDM parameters fixed.
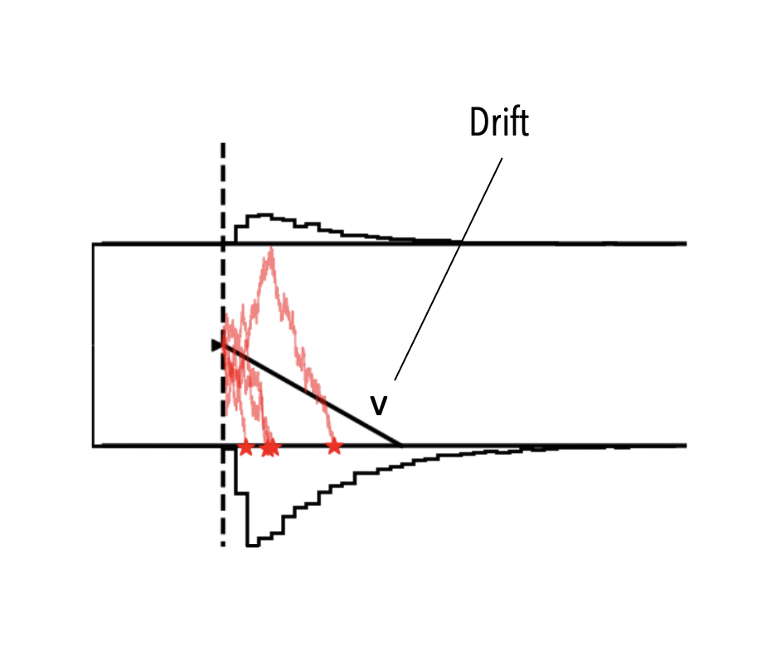
Fixing parameters reduces model flexibility, so it should be justified by theory, design, or a deliberate comparison.
param_dict_init
{'v': 0.5, 'a': 1.5, 'z': 0.5, 't': 0.5}
ddm_model_only_v = hssm.HSSM(
data=dataset,
model="ddm",
a=param_dict_init["a"],
t=param_dict_init["t"],
z=param_dict_init["z"],
)
Model initialized successfully.
Since we fix all but one parameter, we estimate only one parameter. This is a useful pattern when a parameter is known from design, when a previous analysis justifies a fixed value, or when you want to isolate one cognitive process. The model graph should reflect this choice: we expect only one free random variable, v.
ddm_model_only_v.graph()

ddm_model_only_v.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 4 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
│ Data variables:
│ v (chain, draw) float64 8kB 0.5099 0.5062 0.5062 ... 0.5604 0.4387
│ Attributes:
│ created_at: 2026-07-10T15:48:34.939434+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 3.8603808879852295
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
│ Data variables: (12/18)
│ diverging (chain, draw) bool 1kB False False ... False False
│ n_steps (chain, draw) float64 8kB 3.0 1.0 3.0 ... 1.0 1.0 3.0
│ energy (chain, draw) float64 8kB 1.029e+03 ... 1.031e+03
│ smallest_eigval (chain, draw) float64 8kB nan nan nan ... nan nan nan
│ tree_depth (chain, draw) int64 8kB 2 1 2 1 1 1 2 ... 2 1 2 1 1 2
│ process_time_diff (chain, draw) float64 8kB 6.8e-05 3.6e-05 ... 6.6e-05
│ ... ...
│ step_size_bar (chain, draw) float64 8kB 1.115 1.115 ... 1.364 1.364
│ reached_max_treedepth (chain, draw) bool 1kB False False ... False False
│ energy_error (chain, draw) float64 8kB -0.1347 ... 0.1649
│ perf_counter_start (chain, draw) float64 8kB 7.907e+04 ... 7.907e+04
│ perf_counter_diff (chain, draw) float64 8kB 6.883e-05 ... 6.546e-05
│ step_size (chain, draw) float64 8kB 1.652 1.652 ... 1.263 1.263
│ Attributes:
│ created_at: 2026-07-10T15:48:34.943911+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 3.8603808879852295
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
└── Group: /observed_data
Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2)
Coordinates:
* __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499
* rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1
Data variables:
rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 3...
Attributes:
created_at: 2026-07-10T15:48:34.945551+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.1.0
sample_dims: []
modeling_interface: bambi
modeling_interface_version: 0.18.0pc = az.plot_trace_dist(ddm_model_only_v.traces)
add_trace_reference_lines(pc, {"v": param_dict_init["v"]})

A rank plot complements a trace plot by checking whether chains are sampling from the same distribution. Roughly uniform ranks across chains are consistent with good mixing; visible chain-specific patterns call for further diagnosis.
az.plot_rank(ddm_model_only_v.traces)
<arviz_plots.plot_collection.PlotCollection at 0x130472840>

Specify informative priors¶
model_normal = hssm.HSSM(
data=dataset,
include=[
{
"name": "v",
"prior": {"name": "Normal", "mu": 0, "sigma": 0.01},
}
],
)
Model initialized successfully.
model_normal
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 500
Parameters:
v:
Prior: Normal(mu: 0.0, sigma: 0.01)
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
infer_data_normal = model_normal.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 7 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
pc = az.plot_trace_dist(model_normal.traces)
add_trace_reference_lines(pc, param_dict_init)

The data were generated with v=0.5, a=1.5, z=0.5, and t=0.2. The extremely narrow prior on v pulls its posterior toward zero, and the remaining parameters compensate. The divergences in this fit are a warning that an implausibly restrictive prior can distort both inference and sampler geometry.
Regressions on cognitive parameters¶

HSSM can link individual SSM parameters to trial-level covariates with Bambi-style formulas. This lets you ask questions such as whether a neural signal, condition, or behavioral measure predicts drift rate, boundary separation, or bias.
One parameter as a regression target¶
Simulating Data¶
We simulate data in which drift rate varies with two trial-level covariates. The known coefficients give us a clear recovery target.
# Set up trial by trial parameters
v_intercept = 0.3
x = np.random.uniform(-1, 1, size=1000)
v_x = 0.8
y = np.random.uniform(-1, 1, size=1000)
v_y = 0.3
v_reg_v = v_intercept + (v_x * x) + (v_y * y)
# rest
a_reg_v = 1.5
z_reg_v = 0.5
t_reg_v = 0.1
param_dict_reg_v = dict(
a=1.5, z=0.5, t=0.1, v=v_reg_v, v_x=v_x, v_y=v_y, v_Intercept=v_intercept, theta=0.0
)
# base dataset
dataset_reg_v = hssm.simulate_data(model="ddm", theta=param_dict_reg_v, size=1)
# Adding covariates into the datsaframe
dataset_reg_v["x"] = x
dataset_reg_v["y"] = y
Define the regression¶
The include argument contains one specification per parameter with a regression. Each specification names the parameter, supplies a formula and link, and can define priors for regression coefficients.
Formula syntax follows Bambi and familiar R-style mixed-model notation. HSSM uses Bambi to translate these formulas into a PyMC model. Conceptually, this means the SSM parameter is no longer a single value; it can vary systematically with trial-level or participant-level predictors.
model_reg_v_simple = hssm.HSSM(
data=dataset_reg_v, include=[{"name": "v", "formula": "v ~ 1 + x + y"}]
)
Model initialized successfully.
model_reg_v_simple
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
Param class¶
As illustrated below, there is an alternative way of specifying the parameter specific data via the Param class.
model_reg_v_simple_new = hssm.HSSM(
data=dataset_reg_v, include=[hssm.Param(name="v", formula="v ~ 1 + x + y")]
)
Model initialized successfully.
model_reg_v_simple_new
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
model_reg_v_simple.graph()

print(model_reg_v_simple)
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
Customize parameter-specific priors¶
The default regression specification is often a good starting point. When prior knowledge is available, specify coefficient-level priors explicitly and then verify the resulting model summary before sampling.
model_reg_v = hssm.HSSM(
data=dataset_reg_v,
include=[
{
"name": "v",
"prior": {
"Intercept": {"name": "Uniform", "lower": -3.0, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Uniform(lower: -3.0, upper: 3.0)
v_x ~ Uniform(lower: -1.0, upper: 1.0)
v_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
The model summary now shows v as a regression with an intercept and covariate coefficients. This is the same specification-check step as before, but now the summary should also confirm that the intended predictors entered the model.
infer_data_reg_v = model_reg_v.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [t, a, z, v_Intercept, v_x, v_y]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 12 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
infer_data_reg_v
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499
│ Data variables:
│ a (chain, draw) float64 8kB 1.504 1.545 1.532 ... 1.515 1.543
│ v_Intercept (chain, draw) float64 8kB 0.3631 0.3467 ... 0.3635 0.3426
│ v_x (chain, draw) float64 8kB 0.8948 0.9146 0.882 ... 0.9173 0.927
│ t (chain, draw) float64 8kB 0.1179 0.09665 ... 0.1017 0.08558
│ v_y (chain, draw) float64 8kB 0.4084 0.4319 0.402 ... 0.3774 0.3587
│ z (chain, draw) float64 8kB 0.5079 0.5141 ... 0.4965 0.5019
│ Attributes:
│ created_at: 2026-07-10T15:48:57.382174+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 11.856995820999146
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
│ Data variables: (12/18)
│ diverging (chain, draw) bool 1kB False False ... False False
│ n_steps (chain, draw) float64 8kB 7.0 7.0 3.0 ... 7.0 7.0 7.0
│ energy (chain, draw) float64 8kB 1.983e+03 ... 1.985e+03
│ smallest_eigval (chain, draw) float64 8kB nan nan nan ... nan nan nan
│ tree_depth (chain, draw) int64 8kB 3 3 2 3 3 2 3 ... 3 2 2 3 3 3
│ process_time_diff (chain, draw) float64 8kB 0.004303 ... 0.004226
│ ... ...
│ step_size_bar (chain, draw) float64 8kB 0.5968 0.5968 ... 0.6126
│ reached_max_treedepth (chain, draw) bool 1kB False False ... False False
│ energy_error (chain, draw) float64 8kB 0.3216 0.02889 ... -0.07076
│ perf_counter_start (chain, draw) float64 8kB 7.909e+04 ... 7.909e+04
│ perf_counter_diff (chain, draw) float64 8kB 0.004303 ... 0.00423
│ step_size (chain, draw) float64 8kB 0.7583 0.7583 ... 0.4292
│ Attributes:
│ created_at: 2026-07-10T15:48:57.386813+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 11.856995820999146
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /observed_data
│ Dimensions: (__obs__: 1000, rt,response_extra_dim_0: 2)
│ Coordinates:
│ * __obs__ (__obs__) int64 8kB 0 1 2 3 4 ... 996 997 998 999
│ * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1
│ Data variables:
│ rt,response (__obs__, rt,response_extra_dim_0) float64 16kB ...
│ Attributes:
│ created_at: 2026-07-10T15:48:57.388445+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: []
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
└── Group: /log_likelihood
Dimensions: (chain: 2, draw: 500, __obs__: 1000)
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499
* __obs__ (__obs__) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
Data variables:
rt,response (chain, draw, __obs__) float64 8MB -2.836 -0.8916 ... -1.756
Attributes:
modeling_interface: bambi
modeling_interface_version: 0.18.0# az.plot_forest(model_reg_v.traces)
pc = az.plot_trace_dist(model_reg_v.traces, var_names=["~v"])
add_trace_reference_lines(pc, param_dict_reg_v)

# Looks like parameter recovery was successful
az.summary(model_reg_v.traces, var_names=["~v"])
| mean | sd | eti89_lb | eti89_ub | ess_bulk | ess_tail | r_hat | mcse_mean | mcse_sd | |
|---|---|---|---|---|---|---|---|---|---|
| a | 1.504 | 0.026 | 1.5 | 1.5 | 848 | 718 | 1.00 | 0.0009 | 0.00065 |
| v_Intercept | 0.286 | 0.031 | 0.24 | 0.34 | 1038 | 754 | 1.00 | 0.00097 | 0.00069 |
| v_x | 0.871 | 0.046 | 0.8 | 0.95 | 625 | 443 | 1.00 | 0.0018 | 0.0011 |
| t | 0.129 | 0.018 | 0.1 | 0.16 | 786 | 553 | 1.00 | 0.00064 | 0.0005 |
| v_y | 0.385 | 0.046 | 0.31 | 0.46 | 1131 | 738 | 1.01 | 0.0014 | 0.00087 |
| z | 0.5214 | 0.0113 | 0.5 | 0.54 | 1036 | 725 | 1.00 | 0.00035 | 0.00026 |
Regression with an angle model¶
model_reg_v_angle = hssm.HSSM(
data=dataset_reg_v,
model="angle",
include=[
{
"name": "v",
"prior": {
"Intercept": {
"name": "Uniform",
"lower": -3.0,
"upper": 3.0,
},
"x": {
"name": "Uniform",
"lower": -1.0,
"upper": 1.0,
},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_angle.graph()

trace_reg_v_angle = model_reg_v_angle.sample(
sampler="pymc",
chains=1,
cores=1,
draws=500,
tune=500,
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (1 chains in 1 job) NUTS: [a, theta, t, z, v_Intercept, v_x, v_y]
Output()
Sampling 1 chain for 500 tune and 500 draw iterations (500 + 500 draws total) took 27 seconds. Only one chain was sampled, this makes it impossible to run some convergence checks
pc = az.plot_trace_dist(model_reg_v_angle.traces, var_names=["~v"])
add_trace_reference_lines(pc, param_dict_reg_v)

The posterior for theta is close to zero, as expected for data generated by a standard DDM. The remaining parameters and regression coefficients can then be interpreted with the same diagnostic workflow.
Regress multiple parameters¶
We now fit regressions for both v and a. Only v truly varies with the simulated covariates, so the a coefficients should be centered near zero.
# Instantiate our hssm model
from copy import deepcopy
param_dict_reg_v_a = deepcopy(param_dict_reg_v)
param_dict_reg_v_a["a_Intercept"] = param_dict_reg_v_a["a"]
param_dict_reg_v_a["a_x"] = 0
param_dict_reg_v_a["a_y"] = 0
hssm_reg_v_a_angle = hssm.HSSM(
data=dataset_reg_v,
model="angle",
include=[
{
"name": "v",
"prior": {
"Intercept": {"name": "Uniform", "lower": -3.0, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
},
{
"name": "a",
"prior": {
"Intercept": {"name": "Uniform", "lower": 0.5, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "a ~ 1 + x + y",
},
],
)
Model initialized successfully.
hssm_reg_v_a_angle
Hierarchical Sequential Sampling Model
Model: angle
Response variable: rt,response
Likelihood: approx_differentiable
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Uniform(lower: -3.0, upper: 3.0)
v_x ~ Uniform(lower: -1.0, upper: 1.0)
v_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (-3.0, 3.0)
a:
Formula: a ~ 1 + x + y
Priors:
a_Intercept ~ Uniform(lower: 0.5, upper: 3.0)
a_x ~ Uniform(lower: -1.0, upper: 1.0)
a_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (0.3, 3.0)
z:
Prior: Uniform(lower: 0.1, upper: 0.9)
Explicit bounds: (0.1, 0.9)
t:
Prior: Uniform(lower: 0.001, upper: 2.0)
Explicit bounds: (0.001, 2.0)
theta:
Prior: Uniform(lower: -0.1, upper: 1.3)
Explicit bounds: (-0.1, 1.3)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
hssm_reg_v_a_angle.graph()

infer_data_reg_v_a = hssm_reg_v_a_angle.sample(
sampler="pymc",
chains=2,
cores=1,
draws=500,
tune=500,
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [theta, t, z, v_Intercept, v_x, v_y, a_Intercept, a_x, a_y]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 53 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
az.summary(
infer_data_reg_v_a, var_names=["~a", "~v"]
) # , var_names=["~rt,response_a"])
| mean | sd | eti89_lb | eti89_ub | ess_bulk | ess_tail | r_hat | mcse_mean | mcse_sd | |
|---|---|---|---|---|---|---|---|---|---|
| theta | 0.043 | 0.022 | 0.01 | 0.078 | 490 | 498 | 1.01 | 0.00098 | 0.00064 |
| a_y | 0.008 | 0.037 | -0.051 | 0.072 | 1187 | 697 | 1.00 | 0.0011 | 0.00081 |
| v_Intercept | 0.274 | 0.032 | 0.22 | 0.33 | 726 | 749 | 1.00 | 0.0012 | 0.0009 |
| v_x | 0.867 | 0.05 | 0.79 | 0.95 | 697 | 338 | 1.01 | 0.0019 | 0.0013 |
| t | 0.106 | 0.024 | 0.066 | 0.14 | 574 | 479 | 1.00 | 0.001 | 0.00074 |
| v_y | 0.387 | 0.046 | 0.31 | 0.46 | 864 | 714 | 1.00 | 0.0016 | 0.001 |
| z | 0.5278 | 0.0124 | 0.51 | 0.55 | 791 | 814 | 1.00 | 0.00044 | 0.00031 |
| a_Intercept | 1.565 | 0.05 | 1.5 | 1.6 | 427 | 329 | 1.01 | 0.0025 | 0.0017 |
| a_x | 0.026 | 0.044 | -0.041 | 0.099 | 930 | 568 | 1.00 | 0.0015 | 0.001 |
pc = az.plot_trace_dist(hssm_reg_v_a_angle.traces, var_names=["~v", "~a"])
add_trace_reference_lines(pc, param_dict_reg_v_a)

The v coefficients recover the simulated relationship. The a coefficients remain near zero, which is the expected result because the data-generating process did not vary a with these covariates.
Categorical covariates¶
# Set up trial by trial parameters
x = np.random.choice(4, size=1000).astype(int)
x_offset = np.array([0, 1, -0.5, 0.75])
y = np.random.uniform(-1, 1, size=1000)
v_y = 0.3
v_reg_v = 0 + (v_y * y) + x_offset[x]
# rest
a_reg_v = 1.5
z_reg_v = 0.5
t_reg_v = 0.1
# base dataset
dataset_reg_v_cat = hssm.simulate_data(
model="ddm", theta=dict(v=v_reg_v, a=a_reg_v, z=z_reg_v, t=t_reg_v), size=1
)
# Adding covariates into the datsaframe
dataset_reg_v_cat["x"] = x
dataset_reg_v_cat["y"] = y
model_reg_v_cat = hssm.HSSM(
data=dataset_reg_v_cat,
model="angle",
include=[
{
"name": "v",
"formula": "v ~ 0 + C(x) + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_cat.graph()

infer_data_reg_v_cat = model_reg_v_cat.sample(
sampler="pymc",
chains=2,
cores=1,
draws=500,
tune=500,
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [a, theta, t, z, v_C(x), v_y]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 39 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
az.plot_forest(infer_data_reg_v_cat, var_names=["~v"])
<arviz_plots.plot_collection.PlotCollection at 0x136e9baa0>

Hierarchical participant effects¶
Next we simulate data from 15 participants, each with 200 trials. A hierarchy lets participant-level estimates share information through a group distribution while preserving individual differences.
Simulate Data¶
# Make some hierarchical data
n_participants = 15 # number of participants
n_trials = 200 # number of trials per participant
sd_v = 0.5 # sd for v-intercept
mean_v = 0.5 # mean for v-intercept
data_list = []
for i in range(n_participants):
# Make parameters for participant i
v_intercept_hier = np.random.normal(mean_v, sd_v, size=1)
x = np.random.uniform(-1, 1, size=n_trials)
v_x_hier = 0.8
y = np.random.uniform(-1, 1, size=n_trials)
v_y_hier = 0.3
v_hier = v_intercept_hier + (v_x_hier * x) + (v_y_hier * y)
a_hier = 1.5
t_hier = 0.5
z_hier = 0.5
# true_values = np.column_stack(
# [v, np.repeat([[1.5, 0.5, 0.5, 0.0]], axis=0, repeats=n_trials)]
# )
data_tmp = hssm.simulate_data(
model="ddm", theta=dict(v=v_hier, a=a_hier, z=z_hier, t=t_hier), size=1
)
data_tmp["participant_id"] = i
data_tmp["x"] = x
data_tmp["y"] = y
data_list.append(data_tmp)
# Make single dataframe out of participant-wise datasets
dataset_reg_v_hier = pd.concat(data_list)
dataset_reg_v_hier
| rt | response | participant_id | x | y | |
|---|---|---|---|---|---|
| 0 | 0.848884 | 1.0 | 0 | 0.898214 | -0.716783 |
| 1 | 1.411499 | 1.0 | 0 | 0.647320 | 0.698531 |
| 2 | 1.657835 | 1.0 | 0 | -0.876222 | 0.464074 |
| 3 | 3.335139 | 1.0 | 0 | -0.697772 | -0.701055 |
| 4 | 2.378305 | 1.0 | 0 | -0.357845 | -0.754203 |
| ... | ... | ... | ... | ... | ... |
| 195 | 0.899326 | 1.0 | 14 | -0.796075 | -0.084597 |
| 196 | 0.908496 | 1.0 | 14 | 0.117435 | -0.647280 |
| 197 | 1.629932 | 1.0 | 14 | -0.791289 | 0.220870 |
| 198 | 3.750777 | -1.0 | 14 | -0.970591 | -0.621179 |
| 199 | 1.122219 | 1.0 | 14 | 0.454010 | -0.394580 |
3000 rows × 5 columns
We use v ~ 1 + (1|participant_id) + x + y. The random-intercept term (1|participant_id) gives each participant an offset around the group intercept; the remaining coefficients are shared across participants. The hierarchy lets participants borrow strength from the group while still allowing individual differences.
Basic Hierarchical Model¶
model_reg_v_angle_hier = hssm.HSSM(
data=dataset_reg_v_hier,
model="angle",
noncentered=True,
include=[
{
"name": "v",
"prior": {
"Intercept": {
"name": "Normal",
"mu": 0.0,
"sigma": 0.5,
},
"x": {"name": "Normal", "mu": 0.0, "sigma": 0.5},
"y": {"name": "Normal", "mu": 0.0, "sigma": 0.5},
},
"formula": "v ~ 1 + (1|participant_id) + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_angle_hier.graph()

jax.config.update("jax_enable_x64", False)
model_reg_v_angle_hier.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals. Parallel sampling might not work with `jax` backend and the PyMC NUTS sampler on some platforms. Please consider using `numpyro`, `blackjax`, or `nutpie` sampler if that is a problem.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [a, theta, t, z, v_Intercept, v_x, v_y, v_1|participant_id_sigma, v_1|participant_id_offset]
Output()
/Users/krishnbera/Documents/HSSMSpine/_local/venvs/addressing-pr-comments-on-1043-hssm/lib/python3.12/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run LANLogpOp's perform method. Set `pytensor.config.compiler_verbose = True` to see more details. warnings.warn( /Users/krishnbera/Documents/HSSMSpine/_local/venvs/addressing-pr-comments-on-1043-hssm/lib/python3.12/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run LANLogpVJPOp's perform method. Set `pytensor.config.compiler_verbose = True` to see more details. warnings.warn(
/Users/krishnbera/Documents/HSSMSpine/_local/venvs/addressing-pr-comments-on-1043-hssm/lib/python3.12/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run LANLogpOp's perform method. Set `pytensor.config.compiler_verbose = True` to see more details. warnings.warn( /Users/krishnbera/Documents/HSSMSpine/_local/venvs/addressing-pr-comments-on-1043-hssm/lib/python3.12/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run LANLogpVJPOp's perform method. Set `pytensor.config.compiler_verbose = True` to see more details. warnings.warn(
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 204 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 500,
│ v_1|participant_id__factor_dim: 15)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 ... 496 497 498 499
│ * v_1|participant_id__factor_dim (v_1|participant_id__factor_dim) <U2 120B ...
│ Data variables:
│ a (chain, draw) float64 8kB 1.552 ... 1.502
│ theta (chain, draw) float64 8kB 0.0491 ... 0.03026
│ v_1|participant_id_offset (chain, draw, v_1|participant_id__factor_dim) float64 120kB ...
│ v_Intercept (chain, draw) float64 8kB 0.3047 ... 0.06821
│ v_x (chain, draw) float64 8kB 0.8202 ... 0.8349
│ t (chain, draw) float64 8kB 0.5002 ... 0.5174
│ v_y (chain, draw) float64 8kB 0.342 ... 0.3506
│ z (chain, draw) float64 8kB 0.5005 ... 0.497
│ v_1|participant_id (chain, draw, v_1|participant_id__factor_dim) float64 120kB ...
│ v_1|participant_id_sigma (chain, draw) float64 8kB 0.45 ... 0.5482
│ Attributes:
│ created_at: 2026-07-10T15:54:31.010483+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 204.4957389831543
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
│ Data variables: (12/18)
│ diverging (chain, draw) bool 1kB False False ... False False
│ n_steps (chain, draw) float64 8kB 15.0 15.0 ... 15.0 31.0
│ energy (chain, draw) float64 8kB 5.495e+03 ... 5.491e+03
│ smallest_eigval (chain, draw) float64 8kB nan nan nan ... nan nan nan
│ tree_depth (chain, draw) int64 8kB 4 4 5 3 3 5 5 ... 5 4 3 3 4 5
│ process_time_diff (chain, draw) float64 8kB 0.216 0.2189 ... 0.3655
│ ... ...
│ step_size_bar (chain, draw) float64 8kB 0.1547 0.1547 ... 0.1448
│ reached_max_treedepth (chain, draw) bool 1kB False False ... False False
│ energy_error (chain, draw) float64 8kB -0.3602 -0.09013 ... 0.315
│ perf_counter_start (chain, draw) float64 8kB 7.933e+04 ... 7.943e+04
│ perf_counter_diff (chain, draw) float64 8kB 0.08283 0.08416 ... 0.1241
│ step_size (chain, draw) float64 8kB 0.1305 0.1305 ... 0.1019
│ Attributes:
│ created_at: 2026-07-10T15:54:31.017396+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 204.4957389831543
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /observed_data
│ Dimensions: (__obs__: 3000, rt,response_extra_dim_0: 2)
│ Coordinates:
│ * __obs__ (__obs__) int64 24kB 0 1 2 3 ... 2997 2998 2999
│ * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1
│ Data variables:
│ rt,response (__obs__, rt,response_extra_dim_0) float64 48kB ...
│ Attributes:
│ created_at: 2026-07-10T15:54:31.019039+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: []
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
└── Group: /log_likelihood
Dimensions: (chain: 2, draw: 500, __obs__: 3000)
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499
* __obs__ (__obs__) int64 24kB 0 1 2 3 4 5 ... 2995 2996 2997 2998 2999
Data variables:
rt,response (chain, draw, __obs__) float64 24MB -0.2871 -0.3997 ... -0.4504
Attributes:
modeling_interface: bambi
modeling_interface_version: 0.18.0Inspect the posterior to distinguish group-level effects from participant-level variation and to confirm that the chains mix well. In hierarchical models, it is especially useful to separate population-level parameters from participant-specific offsets before interpreting the substantive effects.
az.plot_forest(model_reg_v_angle_hier.traces, var_names=["~v", "~a"], combined=False)
<arviz_plots.plot_collection.PlotCollection at 0x13374c2f0>

4. Validate and compare models¶
Model comparison asks how well competing models predict the same data while accounting for fit and complexity. It comes after diagnostics and posterior predictive checks because a model with poor sampling behavior or obvious predictive failures is not a strong scientific candidate, even if a comparison table looks favorable. Here the data are generated with a=1.5, and we compare three DDMs that fix a too low (1.3), correctly (1.5), or too high (1.7).
We use ArviZ's compare() function with expected log predictive density from leave-one-out cross-validation (elpd_loo). Higher expected predictive accuracy is better, but close differences should be interpreted as uncertainty rather than a hard ranking.
Data Simulation¶
# Parameters
param_dict_mod_comp = dict(v=0.5, a=1.5, z=0.5, t=0.2)
# Simulation
dataset_model_comp = hssm.simulate_data(
model="ddm", theta=param_dict_mod_comp, size=500
)
print(dataset_model_comp)
rt response 0 1.611082 1.0 1 0.669893 -1.0 2 1.986627 1.0 3 0.947021 1.0 4 3.805303 1.0 .. ... ... 495 0.671116 1.0 496 1.596365 -1.0 497 1.860955 1.0 498 0.907639 1.0 499 1.538692 1.0 [500 rows x 2 columns]
Defining the Models¶
# "under-specified" model — boundary fixed too low
model_model_comp_1 = hssm.HSSM(
data=dataset_model_comp,
model="ddm",
a=1.3,
)
Model initialized successfully.
# "correct" model — boundary fixed at the data-generating value
model_model_comp_2 = hssm.HSSM(
data=dataset_model_comp,
model="ddm",
a=1.5,
)
Model initialized successfully.
# "over-specified" model — boundary fixed too high
model_model_comp_3 = hssm.HSSM(
data=dataset_model_comp,
model="ddm",
a=1.7,
)
Model initialized successfully.
infer_data_model_comp_1 = model_model_comp_1.sample(
sampler="pymc",
cores=1,
chains=2,
draws=500,
tune=500,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 5 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
infer_data_model_comp_2 = model_model_comp_2.sample(
sampler="pymc",
cores=1,
chains=2,
draws=500,
tune=500,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 5 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
infer_data_model_comp_3 = model_model_comp_3.sample(
sampler="pymc",
cores=1,
chains=2,
draws=500,
tune=500,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 7 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
Compare¶
compare_data = az.compare(
{
"a_fixed_1.3(under)": model_model_comp_1.traces,
"a_fixed_1.5(correct)": model_model_comp_2.traces,
"a_fixed_1.7(over)": model_model_comp_3.traces,
}
)
compare_data
| rank | elpd_diff | dse | p_worse | diag_diff | diag_elpd | p | elpd | se | weight | |
|---|---|---|---|---|---|---|---|---|---|---|
| a_fixed_1.5(correct) | 0 | 0.0 | 0.0 | NaN | 2.6 | -1010.0 | 24.0 | 0.99 | ||
| a_fixed_1.7(over) | 1 | -11.0 | 4.2 | 1.0 | 2.7 | -1020.0 | 24.0 | 0.00 | ||
| a_fixed_1.3(under) | 2 | -10.0 | 5.5 | 1.0 | 2.5 | -1020.0 | 27.0 | 0.01 |
The correctly specified model should receive the strongest support in this controlled example. In applied work, treat close comparisons as uncertainty rather than as a definitive winner, and use the comparison as one piece of evidence alongside posterior predictive checks and domain knowledge.
az.plot_compare(compare_data)
<arviz_plots.plot_collection.PlotCollection at 0x13b80f4a0>

The forest plot helps explain why the misspecified models fit poorly: when a is fixed incorrectly, other parameters shift to compensate. This is a useful habit after model comparison: look at the parameter estimates to understand what each model had to do in order to fit the data.
az.plot_forest(
{
"a_fixed_1.3(under)": model_model_comp_1.traces,
"a_fixed_1.5(correct)": model_model_comp_2.traces,
"a_fixed_1.7(over)": model_model_comp_3.traces,
}
)
<arviz_plots.plot_collection.PlotCollection at 0x13b07f500>

Simulation and model configuration under the hood¶
The following optional examples show trial-wise simulation, model discovery, and direct use of ssm-simulators. They are useful when you move beyond the introductory DDM workflow.
Trial-wise simulation with HSSM¶
# a changes trial wise
a_trialwise = np.random.normal(loc=2, scale=0.3, size=1000)
dataset_a_trialwise = hssm.simulate_data(
model="ddm",
theta=dict(
v=v_true,
a=a_trialwise,
z=z_true,
t=t_true,
),
size=1,
)
dataset_a_trialwise
| rt | response | |
|---|---|---|
| 0 | 3.582996 | 1.0 |
| 1 | 4.052526 | -1.0 |
| 2 | 1.358000 | 1.0 |
| 3 | 5.685522 | 1.0 |
| 4 | 2.902158 | 1.0 |
| ... | ... | ... |
| 995 | 5.675550 | -1.0 |
| 996 | 4.013608 | 1.0 |
| 997 | 2.537024 | 1.0 |
| 998 | 4.713144 | 1.0 |
| 999 | 1.411000 | 1.0 |
1000 rows × 2 columns
HSSM can simulate many supported models. The models available for simulation and the models with packaged likelihood functions are related but not identical; inspect the supported-model list when choosing a model for inference.
hssm.HSSM.supported_models
('ddm',
'ddm_sdv',
'full_ddm',
'angle',
'levy',
'ornstein',
'weibull',
'race_no_bias_angle_4',
'ddm_seq2_no_bias',
'lba3',
'lba2',
'racing_diffusion_3',
'poisson_race',
'softmax_inv_temperature_2',
'softmax_inv_temperature_3')
The model configuration records parameter names, default likelihoods, bounds, and prior settings. It is useful when you are adapting a built-in model or contributing a new one.
hssm.modelconfig.get_default_model_config("ddm")
{'response': ['rt', 'response'],
'list_params': ['v', 'a', 'z', 't'],
'choices': [-1, 1],
'description': 'The Drift Diffusion Model (DDM)',
'likelihoods': {'analytical': {'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None},
'approx_differentiable': {'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None},
'blackbox': {'loglik': <function hssm.likelihoods.blackbox.hddm_to_hssm.<locals>.outer(data: numpy.ndarray, *args, **kwargs)>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}}}
For simulation, two configuration entries are particularly useful:
list_paramsgives the parameter order and names expected by the model.likelihoodsrecords the availableanalytical,approx_differentiable, andblackboxlikelihood options, together with their bounds and defaults.
Direct ssm-simulators usage¶
import numpy as np
import pandas as pd
from ssms.basic_simulators.simulator import simulator
# a changes trial wise
theta_mat = np.zeros((1000, 4))
theta_mat[:, 0] = v_true # v
theta_mat[:, 1] = a_trialwise # a
theta_mat[:, 2] = z_true # z
theta_mat[:, 3] = t_true # t
# simulate data
sim_out_trialwise = simulator(
theta=theta_mat, # parameter_matrix
model="ddm", # specify model (many are included in ssms)
n_samples=1, # number of samples for each set of parameters
# (plays the role of `size` parameter in `hssm.simulate_data`)
)
# Turn into nice dataset
dataset_trialwise = pd.DataFrame(
np.column_stack(
[sim_out_trialwise["rts"][:, 0], sim_out_trialwise["choices"][:, 0]]
),
columns=["rt", "response"],
)
dataset_trialwise
| rt | response | |
|---|---|---|
| 0 | 5.677045 | 1.0 |
| 1 | 4.400869 | 1.0 |
| 2 | 5.982333 | 1.0 |
| 3 | 4.487048 | 1.0 |
| 4 | 5.037333 | 1.0 |
| ... | ... | ... |
| 995 | 2.349885 | 1.0 |
| 996 | 4.010667 | 1.0 |
| 997 | 2.008332 | 1.0 |
| 998 | 2.842229 | 1.0 |
| 999 | 3.402905 | 1.0 |
1000 rows × 2 columns
For most HSSM workflows, hssm.simulate_data() is the clearest starting point. Direct ssm-simulators access is useful when you need the simulator’s lower-level output or a custom simulation pipeline.
5. Optional advanced extensions¶
The remaining sections show how HSSM connects to the broader computational ecosystem. They are optional for a first analysis, but useful when you need custom simulators, likelihoods, or a lower-level PyMC model. If you are new to HSSM, it is reasonable to stop after model comparison and return here once you need more control.

hssm.config.default_model_config["ddm"].keys()
dict_keys(['response', 'list_params', 'choices', 'description', 'likelihoods'])
A model configuration describes its response coding, parameter list, description, and available likelihood definitions. Inspecting it is a practical starting point for advanced customization.
hssm.config.default_model_config["ddm"]["likelihoods"]
{'analytical': {'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None},
'approx_differentiable': {'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None},
'blackbox': {'loglik': <function hssm.likelihoods.blackbox.hddm_to_hssm.<locals>.outer(data: numpy.ndarray, *args, **kwargs)>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}}
The DDM configuration exposes three likelihood kinds: analytical, approx_differentiable, and blackbox. The kind determines the representation of the likelihood and which samplers are compatible.
hssm.config.default_model_config["ddm"]["likelihoods"]["analytical"]
{'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}
The key entries are loglik, backend, bounds, and default_priors. Bounds constrain valid parameter regions, while defaults provide a usable prior specification when one is not supplied explicitly.
An approx_differentiable likelihood can be represented by a differentiable approximation, such as a likelihood approximation network. HSSM can evaluate compatible likelihoods through PyTensor or JAX backends.
hssm.config.default_model_config["ddm"]["likelihoods"]["approx_differentiable"]
{'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None}
For packaged approximate likelihoods, loglik may point to an ONNX model. ONNX is a portable format for neural-network likelihood approximators. The backend determines whether HSSM evaluates the likelihood through PyTensor or JAX, which in turn affects compatible MCMC samplers.
The practical takeaway is that HSSM keeps the user-facing model specification stable while allowing different likelihood representations underneath.
hssm_alternative_model = hssm.HSSM(
data=dataset,
model="ddm",
loglik_kind="approx_differentiable",
)
Model initialized successfully.
hssm_alternative_model.loglik_kind
'approx_differentiable'
This model uses an approx_differentiable LAN likelihood rather than the analytical likelihood used in the first DDM example. The assumed generative model remains the DDM.
hssm_alternative_model.sample(
sampler="pymc",
cores=1,
chains=2,
draws=500,
tune=500,
idata_kwargs=dict(
log_likelihood=False
), # model comparison metrics usually need this!
mp_ctx="spawn",
progressbar=PYMC_PROGRESS,
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 17 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
<xarray.DataTree>
Group: /
├── Group: /posterior
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
│ Data variables:
│ v (chain, draw) float64 8kB 0.5015 0.5272 0.4783 ... 0.5475 0.4499
│ t (chain, draw) float64 8kB 0.4922 0.4751 0.4638 ... 0.5117 0.4951
│ a (chain, draw) float64 8kB 1.417 1.422 1.401 ... 1.407 1.447 1.385
│ z (chain, draw) float64 8kB 0.5013 0.4609 0.4599 ... 0.5193 0.4787
│ Attributes:
│ created_at: 2026-07-10T15:55:12.817765+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 16.581934928894043
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
├── Group: /sample_stats
│ Dimensions: (chain: 2, draw: 500)
│ Coordinates:
│ * chain (chain) int64 16B 0 1
│ * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
│ Data variables: (12/18)
│ diverging (chain, draw) bool 1kB False False ... False False
│ n_steps (chain, draw) float64 8kB 3.0 3.0 3.0 ... 3.0 3.0 7.0
│ energy (chain, draw) float64 8kB 1.031e+03 ... 1.034e+03
│ smallest_eigval (chain, draw) float64 8kB nan nan nan ... nan nan nan
│ tree_depth (chain, draw) int64 8kB 2 2 2 3 2 3 3 ... 2 4 3 2 2 3
│ process_time_diff (chain, draw) float64 8kB 0.003998 ... 0.01018
│ ... ...
│ step_size_bar (chain, draw) float64 8kB 0.631 0.631 ... 0.5667
│ reached_max_treedepth (chain, draw) bool 1kB False False ... False False
│ energy_error (chain, draw) float64 8kB 0.2594 -0.2313 ... -0.806
│ perf_counter_start (chain, draw) float64 8kB 7.946e+04 ... 7.947e+04
│ perf_counter_diff (chain, draw) float64 8kB 0.003756 ... 0.009484
│ step_size (chain, draw) float64 8kB 0.9894 0.9894 ... 0.5571
│ Attributes:
│ created_at: 2026-07-10T15:55:12.822852+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.2.0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 6.1.0
│ sample_dims: ['chain', 'draw']
│ sampling_time: 16.581934928894043
│ tuning_steps: 500
│ modeling_interface: bambi
│ modeling_interface_version: 0.18.0
└── Group: /observed_data
Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2)
Coordinates:
* __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499
* rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1
Data variables:
rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 3...
Attributes:
created_at: 2026-07-10T15:55:12.824755+00:00
creation_library: ArviZ
creation_library_version: 1.2.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 6.1.0
sample_dims: []
modeling_interface: bambi
modeling_interface_version: 0.18.0az.plot_forest(hssm_alternative_model.traces)
<arviz_plots.plot_collection.PlotCollection at 0x1351a53d0>

You can also provide a custom likelihood directly. The next section illustrates the non-differentiable blackbox case.
Black-box likelihoods¶

A black-box likelihood is a Python callable that returns trial-wise log likelihoods. It is useful when you can evaluate a model numerically but do not have a differentiable likelihood representation.
Because black-box likelihoods are generally non-differentiable, HSSM uses a gradient-free sampling strategy by default. This makes them flexible, but they are usually slower and require especially careful diagnostics.
Simulating simple dataset from the DDM¶
As always, let's begin by generating some simple dataset.
# Set parameters
param_dict_blackbox = dict(v=0.5, a=1.5, z=0.5, t=0.5)
# Simulate
dataset_blackbox = hssm.simulate_data(model="ddm", theta=param_dict_blackbox, size=1000)
Define the likelihood¶
The callable receives the observed data and model parameters, then returns trial-wise log likelihoods. In this demonstration it delegates to a DDM likelihood, but the same interface can wrap an appropriate custom computation.
def my_blackbox_loglik(data, v, a, z, t, err=1e-8):
"""Create a custom blackbox likelihood function."""
data = data[:, 0] * data[:, 1]
data_nrows = data.shape[0]
# Our function expects inputs as float64, but they are not guaranteed to
# come in as such --> we type convert
return hddm_wfpt.wfpt.wiener_logp_array(
np.float64(data),
(np.ones(data_nrows) * v).astype(np.float64),
np.ones(data_nrows) * 0,
(np.ones(data_nrows) * 2 * a).astype(np.float64),
(np.ones(data_nrows) * z).astype(np.float64),
np.ones(data_nrows) * 0,
(np.ones(data_nrows) * t).astype(np.float64),
np.ones(data_nrows) * 0,
err,
1,
)
Define HSSM class with our Blackbox Likelihood¶
Construct the HSSM model as usual, passing the callable as loglik and declaring loglik_kind="blackbox". Bounds remain important because they define the region where the custom likelihood is valid.
blackbox_model = hssm.HSSM(
data=dataset_blackbox,
model="ddm",
loglik=my_blackbox_loglik,
loglik_kind="blackbox",
model_config={
"bounds": {
"v": (-10.0, 10.0),
"a": (0.5, 5.0),
"z": (0.0, 1.0),
}
},
t=bmb.Prior("Uniform", lower=0.0, upper=2.0),
)
Model initialized successfully.
blackbox_model.graph()

sample = blackbox_model.sample(progressbar=PYMC_PROGRESS)
Using default initvals.
Multiprocess sampling (4 chains in 4 jobs) CompoundStep >Slice: [t] >Slice: [a] >Slice: [z] >Slice: [v]
Output()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 12 seconds.
Black-box likelihoods default to a gradient-free Slice sampler. You may choose another suitable PyMC sampler, but gradient-based JAX samplers are not compatible with a non-differentiable likelihood.
Results¶
az.summary(sample)
| mean | sd | eti89_lb | eti89_ub | ess_bulk | ess_tail | r_hat | mcse_mean | mcse_sd | |
|---|---|---|---|---|---|---|---|---|---|
| v | 0.547 | 0.035 | 0.49 | 0.6 | 1297 | 1615 | 1.00 | 0.00097 | 0.00068 |
| t | 0.501 | 0.0213 | 0.47 | 0.53 | 1236 | 1885 | 1.00 | 0.00061 | 0.00044 |
| a | 1.482 | 0.0267 | 1.4 | 1.5 | 1568 | 2076 | 1.00 | 0.00068 | 0.00049 |
| z | 0.4904 | 0.014 | 0.47 | 0.51 | 1141 | 1451 | 1.00 | 0.00041 | 0.0003 |
pc = az.plot_trace_dist(sample)
add_trace_reference_lines(pc, param_dict_blackbox)

Low-level PyMC integration¶
HSSM can also expose sequential-sampling random variables for use inside a custom PyMC model. This is an advanced path for models that require structure beyond the high-level HSSM interface.
See the low-level PyMC tutorial for a focused follow-up example.
# DDM models (the Wiener First-Passage Time distribution)
from hssm.distribution_utils import make_distribution
from hssm.likelihoods import DDM
Simulate some data¶
# Simulate
param_dict_pymc = dict(v=0.5, a=1.5, z=0.5, t=0.5)
dataset_pymc = hssm.simulate_data(model="ddm", theta=param_dict_pymc, size=1000)
Build a custom PyMC Model¶
We can now use our custom random variable DDM directly in a PyMC model.
import pymc as pm
with pm.Model() as ddm_pymc:
v = pm.Uniform("v", lower=-10.0, upper=10.0)
a = pm.HalfNormal("a", sigma=2.0)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
ddm = DDM(
"DDM",
observed=dataset_pymc[["rt", "response"]].values,
v=v,
a=a,
z=z,
t=t,
)
Let's check the model graph:
pm.model_to_graphviz(model=ddm_pymc)

The custom PyMC graph resembles the HSSM graph because HSSM builds on the same probabilistic-programming components. You can sample the PyMC model directly and use ArviZ for diagnostics.
with ddm_pymc:
ddm_pymc_trace = pm.sample(progressbar=PYMC_PROGRESS)
Initializing NUTS using jitter+adapt_diag... Multiprocess sampling (4 chains in 4 jobs) NUTS: [v, a, z, t]
Output()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 9 seconds.
pc = az.plot_trace_dist(ddm_pymc_trace)
add_trace_reference_lines(pc, param_dict_pymc)

az.plot_forest(ddm_pymc_trace)
<arviz_plots.plot_collection.PlotCollection at 0x12d796cc0>

Alternative models with PyMC¶
from hssm.distribution_utils import make_likelihood_callable
angle_loglik = make_likelihood_callable(
loglik="angle.onnx",
loglik_kind="approx_differentiable",
backend="jax",
params_is_reg=[0, 0, 0, 0, 0],
)
ANGLE = make_distribution(
"angle",
loglik=angle_loglik,
list_params=hssm.defaults.default_model_config["angle"]["list_params"],
)
The params_is_reg vector identifies which likelihood inputs vary trial by trial, as happens when a parameter is produced by a regression formula.
import pymc as pm
# Angle pymc
with pm.Model() as angle_pymc:
# Define parameters
v = pm.Uniform("v", lower=-10.0, upper=10.0)
a = pm.Uniform("a", lower=0.5, upper=2.5)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
theta = pm.Uniform("theta", lower=-0.1, upper=1.0)
# Our RV
angle = ANGLE(
"ANGLE",
v=v,
a=a,
z=z,
t=t,
theta=theta,
observed=dataset_pymc[["rt", "response"]].values,
)
with angle_pymc:
idata_object = pm.sample(nuts_sampler="numpyro", progressbar=EXTERNAL_PROGRESS)
NUTS[numpyro]: [v, a, z, t, theta] sample: 100%|██████████| 2000/2000 [00:25<00:00, 77.08it/s, 15 steps of size 3.56e-01. acc. prob=0.92] sample: 100%|██████████| 2000/2000 [00:29<00:00, 67.88it/s, 15 steps of size 2.69e-01. acc. prob=0.95] sample: 100%|██████████| 2000/2000 [00:25<00:00, 78.17it/s, 7 steps of size 3.37e-01. acc. prob=0.92] sample: 100%|██████████| 2000/2000 [00:25<00:00, 77.70it/s, 23 steps of size 3.51e-01. acc. prob=0.92]
pc = az.plot_trace_dist(idata_object)
add_trace_reference_lines(pc, param_dict_pymc)

Regression directly in PyMC¶
from typing import Optional
def make_params_is_reg_vec(
reg_parameters: Optional[list] = None, parameter_names: Optional[list] = None
):
"""Make a list of Trues and Falses to indicate which parameters are vectors."""
if (not isinstance(reg_parameters, list)) or (
not isinstance(parameter_names, list)
):
raise ValueError("Both reg_parameters and parameter_names should be lists")
bool_list = [0] * len(parameter_names)
for param in reg_parameters:
bool_list[parameter_names.index(param)] = 1
return bool_list
# Set up trial by trial parameters
v_intercept_pymc_reg = 0.3
x_pymc_reg = np.random.uniform(-1, 1, size=1000)
v_x_pymc_reg = 0.8
y_pymc_reg = np.random.uniform(-1, 1, size=1000)
v_y_pymc_reg = 0.3
v_pymc_reg = v_intercept + (v_x * x) + (v_y * y)
param_dict_pymc_reg = dict(
v_Intercept=v_intercept_pymc_reg,
v_x=v_x_pymc_reg,
v_y=v_y_pymc_reg,
v=v_pymc_reg,
a=1.5,
z=0.5,
t=0.1,
theta=0.0,
)
# base dataset
pymc_reg_data = hssm.simulate_data(model="ddm", theta=param_dict_pymc_reg, size=1)
# Adding covariates into the datsaframe
pymc_reg_data["x"] = x
pymc_reg_data["y"] = y
# Make the boolean vector for params_is_reg argument
bool_param_reg = make_params_is_reg_vec(
reg_parameters=["v"],
parameter_names=hssm.defaults.default_model_config["angle"]["list_params"],
)
angle_loglik = make_likelihood_callable(
loglik="angle.onnx",
loglik_kind="approx_differentiable",
backend="jax",
params_is_reg=bool_param_reg,
)
ANGLE = make_distribution(
"angle",
loglik=angle_loglik,
list_params=hssm.defaults.default_model_config["angle"]["list_params"],
)
import pytensor.tensor as pt
with pm.Model(
coords={
"idx": pymc_reg_data.index,
"resp": ["rt", "response"],
"features": ["x", "y"],
}
) as pymc_model_reg:
# Features
x_ = pm.Data("x", pymc_reg_data["x"].values, dims="idx")
y_ = pm.Data("y", pymc_reg_data["y"].values, dims="idx")
# Target
obs = pm.Data("obs", pymc_reg_data[["rt", "response"]].values, dims=("idx", "resp"))
# Priors
a = pm.Uniform("a", lower=0.5, upper=2.5)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
theta = pm.Uniform("theta", lower=-0.1, upper=1.0)
v_Intercept = pm.Uniform("v_Intercept", lower=-3, upper=3)
v_betas = pm.Normal("v_beta", mu=[0, 0], sigma=0.5, dims=("features"))
# Regression equation
v = pm.Deterministic(
"v", v_Intercept + pt.stack([x_, y_], axis=1) @ v_betas, dims="idx"
)
# Our RV
angle = ANGLE(
"angle",
v=v.squeeze(),
a=a,
z=z,
t=t,
theta=theta,
observed=obs,
dims=("idx", "resp"),
)
with pymc_model_reg:
idata_pymc_reg = pm.sample(
nuts_sampler="numpyro",
idata_kwargs={"log_likelihood": True},
progressbar=EXTERNAL_PROGRESS,
)
NUTS[numpyro]: [a, z, t, theta, v_Intercept, v_beta] sample: 100%|██████████| 2000/2000 [00:07<00:00, 269.78it/s, 15 steps of size 2.66e-01. acc. prob=0.91] sample: 100%|██████████| 2000/2000 [00:07<00:00, 279.71it/s, 7 steps of size 3.18e-01. acc. prob=0.88] sample: 100%|██████████| 2000/2000 [00:06<00:00, 317.13it/s, 15 steps of size 3.43e-01. acc. prob=0.86] sample: 100%|██████████| 2000/2000 [00:06<00:00, 330.98it/s, 7 steps of size 2.78e-01. acc. prob=0.94]
az.plot_forest(idata_pymc_reg, var_names=["~v"])
<arviz_plots.plot_collection.PlotCollection at 0x13ffa4ad0>

Conclusion and further resources¶
You have now followed the core HSSM workflow: simulate or load data, define a model, sample the posterior, diagnose MCMC behavior, check predictions, and compare alternatives. From there, use the following resources according to your next question.
Learn more¶
- HSSM foundations: documentation, Getting Started, and hierarchical modeling
- Applied workflows: plotting and the Scientific Workflow tutorial
- Ecosystem tools: PyMC, Bambi, ArviZ, and ssm-simulators
- Community and contributions: GitHub, Discussions, and the contribution guide
As you extend an analysis, keep returning to the same cycle: state the scientific question, make the model assumptions explicit, check sampler diagnostics and predictions, and communicate uncertainty alongside point estimates.
A note on tutorial scale¶
The examples use modest sampling settings so the notebook is practical to run. Before drawing scientific conclusions, increase the number of chains, draws, and tuning iterations; inspect convergence diagnostics; and perform model checks tailored to your data.