This tutorial provides a comprehensive introduction to the HSSM package for Hierarchical Bayesian Estimation of Sequential Sampling Models.
To make the most of the tutorial, let us cover the functionality of the key supporting packages that we use along the way.
Colab Instructions¶
If you would like to run this tutorial on Google colab, please click this link.
Once you are in the colab, follow the installation instructions below and then restart your runtime.
Just uncomment the code in the next code cell and run it!
NOTE:
You may want to switch your runtime to have a GPU or TPU. To do so, go to Runtime > Change runtime type and select the desired hardware accelerator.
Note that if you switch your runtime you have to follow the installation instructions again.
# If running this on Colab, please uncomment the next line
# !pip install git+https://github.com/lnccbrown/HSSM@workshop_tutorial
Basic Imports¶
import warnings
warnings.filterwarnings("ignore")
# Basics
import numpy as np
from matplotlib import pyplot as plt
random_seed_sim = 134
np.random.seed(random_seed_sim)
Data Simulation¶
We will rely on the ssms package for data simulation repeatedly. Let's look at a basic isolated use case below.
As an example, let's use ssms to simulate from the basic Drift Diffusion Model (a running example in this tutorial).
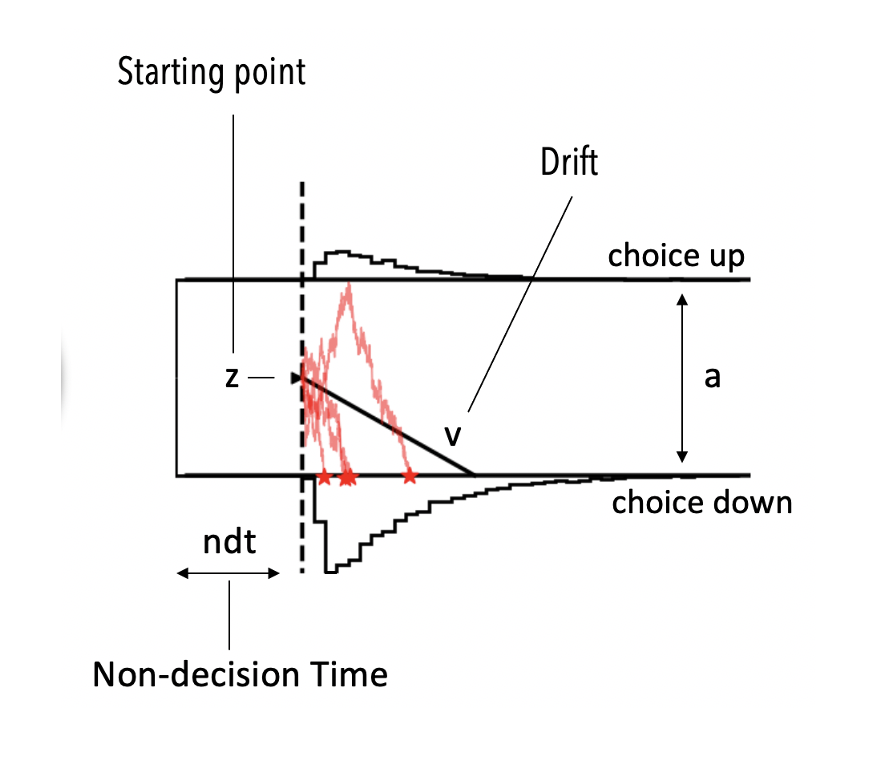
If you are not familiar with the DDM. For now just consider that it has four parameters.
vthe drift rateathe boundary separationtthe non-decision timezthe a priori decision bias (starting point)
Using simulate_data()¶
HSSM comes with a basic simulator function supplied the simulate_data() function. We can use this function to create synthetic datasets.
Below we show the most basic usecase:
We wish to generate 500 datapoints (trials) from the standard Drift Diffusion Model with a fixed parameters, v = 0.5, a = 1.5, z = 0.5, t = 0.5.
Note:
In the course of the tutorial, we will see multiple strategies for synthetic dataset generation, this being the most straightforward one.
# Single dataset
import arviz as az # Visualization
import bambi as bmb # Model construction
import hddm_wfpt
import jax
import pytensor # Graph-based tensor library
import hssm
# pytensor.config.floatX = "float32"
# jax.config.update("jax_enable_x64", False)
v_true = 0.5
a_true = 1.5
z_true = 0.5
t_true = 0.5
# Call the simulator function
dataset = hssm.simulate_data(
model="ddm", theta=dict(v=v_true, a=a_true, z=z_true, t=t_true), size=500
)
dataset
| rt | response | |
|---|---|---|
| 0 | 6.705694 | 1.0 |
| 1 | 1.591768 | 1.0 |
| 2 | 5.085638 | 1.0 |
| 3 | 3.080099 | -1.0 |
| 4 | 1.850662 | 1.0 |
| ... | ... | ... |
| 495 | 2.753426 | 1.0 |
| 496 | 1.122120 | 1.0 |
| 497 | 2.006791 | -1.0 |
| 498 | 3.189377 | 1.0 |
| 499 | 1.829903 | 1.0 |
500 rows × 2 columns
If instead you wish to supply a parameter that varies by trial (a lot more on this later), you can simply supply a vector of parameters to the theta dictionary, when calling the simulator.
Note:
The size argument conceptually functions as number of synthetic datasets. So if you supply a parameter as a (1000,) vector, then the simulator assumes that one dataset consists of 1000 trials, hence if we set the size = 1 as below, we expect in return a dataset with 1000 trials.
# a changes trial wise
a_trialwise = np.random.normal(loc=2, scale=0.3, size=1000)
dataset_a_trialwise = hssm.simulate_data(
model="ddm",
theta=dict(
v=v_true,
a=a_trialwise,
z=z_true,
t=t_true,
),
size=1,
)
dataset_a_trialwise
| rt | response | |
|---|---|---|
| 0 | 2.749979 | 1.0 |
| 1 | 3.617094 | 1.0 |
| 2 | 8.161730 | 1.0 |
| 3 | 2.528078 | 1.0 |
| 4 | 3.657727 | 1.0 |
| ... | ... | ... |
| 995 | 5.848658 | 1.0 |
| 996 | 7.783371 | 1.0 |
| 997 | 5.362286 | 1.0 |
| 998 | 2.358529 | 1.0 |
| 999 | 3.042042 | 1.0 |
1000 rows × 2 columns
If we wish to simulate from another model, we can do so by changing the model string.
The number of models we can simulate differs from the number of models for which we have likelihoods available (both will increase over time). To get the models for which likelihood functions are supplied out of the box, we should inspect hssm.HSSM.supported_models.
hssm.HSSM.supported_models
('ddm',
'ddm_sdv',
'full_ddm',
'angle',
'levy',
'ornstein',
'weibull',
'race_no_bias_angle_4',
'ddm_seq2_no_bias',
'lba3',
'lba2')
If we wish to check more detailed information about a given supported model, we can use the accessor get_default_model_config under hssm.modelconfig. For example, we inspect ddm model configuration below.
hssm.modelconfig.get_default_model_config("ddm")
{'response': ['rt', 'response'],
'list_params': ['v', 'a', 'z', 't'],
'choices': [-1, 1],
'description': 'The Drift Diffusion Model (DDM)',
'likelihoods': {'analytical': {'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None},
'approx_differentiable': {'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None},
'blackbox': {'loglik': <function hssm.likelihoods.blackbox.hddm_to_hssm.<locals>.outer(data: numpy.ndarray, *args, **kwargs)>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}}}
This dictionary contains quite a bit of information. For purposes of simulating data from a given model, we will highlight two aspects:
- The key
list_of_paramsprovides us with the necessary information to define outthetadictionary - The
boundskey inside thelikelihoodssub-dictionaries, provides us with an indication of reasonable parameter values.
The likelihoods dictionary inhabits three sub-directories for the ddm model, since we have all three, an analytical, an approx_differentiable (LAN) and a blackbox likelihood available. For many models, we will be able to access only one or two types of likelihoods.
Using ssm-simulators¶
Internally, HSSM natively makes use of the ssm-simulators package for forward simulation of models.
hssm.simulate_data() functions essentially as a convenience-wrapper.
Below we illustrate how to simulate data using the ssm-simulators package directly, to generate an equivalent dataset as created above. We will use the third way of passing parameters to the simulator, which is as a parameter-matrix.
Notes:
If you pass parameters as a parameter matrix, make sure the column ordering is correct. You can follow the parameter ordering under
hssm.defaults.default_model_config['ddm']['list_params'].This is a minimal example, for more information about the package, check the associated github-page.
import numpy as np
import pandas as pd
from ssms.basic_simulators.simulator import simulator
# a changes trial wise
theta_mat = np.zeros((1000, 4))
theta_mat[:, 0] = v_true # v
theta_mat[:, 1] = a_trialwise # a
theta_mat[:, 2] = z_true # z
theta_mat[:, 3] = t_true # t
# simulate data
sim_out_trialwise = simulator(
theta=theta_mat, # parameter_matrix
model="ddm", # specify model (many are included in ssms)
n_samples=1, # number of samples for each set of parameters
# (plays the role of `size` parameter in `hssm.simulate_data`)
)
# Turn into nice dataset
dataset_trialwise = pd.DataFrame(
np.column_stack(
[sim_out_trialwise["rts"][:, 0], sim_out_trialwise["choices"][:, 0]]
),
columns=["rt", "response"],
)
dataset_trialwise
| rt | response | |
|---|---|---|
| 0 | 3.150271 | 1.0 |
| 1 | 1.444507 | 1.0 |
| 2 | 4.544335 | 1.0 |
| 3 | 1.928551 | 1.0 |
| 4 | 5.318682 | 1.0 |
| ... | ... | ... |
| 995 | 0.925058 | 1.0 |
| 996 | 2.266826 | 1.0 |
| 997 | 4.174062 | 1.0 |
| 998 | 2.482133 | 1.0 |
| 999 | 1.970486 | 1.0 |
1000 rows × 2 columns
We will stick to hssm.simulate_data() in this tutorial, to keep things simple.
ArviZ for Plotting¶

We use the ArviZ package for most of our plotting needs. ArviZ is a useful aid for plotting when doing anything Bayesian.
It works with HSSM out of the box, by virtue of HSSMs reliance on PyMC for model construction and sampling.
Checking out the ArviZ Documentation is a good idea to give you communication superpowers for not only your HSSM results, but also other libraries in the Bayesian Toolkit such as NumPyro or STAN.
We will see ArviZ plots throughout the notebook.
Main Tutorial¶
Initial Dataset¶
Let's proceed to simulate a simple dataset for our first example.
# Specify
param_dict_init = dict(
v=v_true,
a=a_true,
z=z_true,
t=t_true,
)
dataset = hssm.simulate_data(
model="ddm",
theta=param_dict_init,
size=500,
)
dataset
| rt | response | |
|---|---|---|
| 0 | 1.908792 | 1.0 |
| 1 | 2.700515 | 1.0 |
| 2 | 5.079576 | -1.0 |
| 3 | 0.957307 | -1.0 |
| 4 | 3.759613 | -1.0 |
| ... | ... | ... |
| 495 | 1.493450 | 1.0 |
| 496 | 2.354721 | 1.0 |
| 497 | 1.888187 | 1.0 |
| 498 | 1.112517 | 1.0 |
| 499 | 0.654334 | 1.0 |
500 rows × 2 columns
First HSSM Model¶
In this example we will use the analytical likelihood function computed as suggested in this paper.
Instantiate the model¶
To instantiate our HSSM class, in the simplest version, we only need to provide an appropriate dataset.
The dataset is expected to be a pandas.DataFrame with at least two columns, respectively called rt (for reaction time) and response.
Our data simulated above is already in the correct format, so let us try to construct the class.
NOTE:
If you are a user of the HDDM python package, this workflow should seem very familiar.
simple_ddm_model = hssm.HSSM(data=dataset)
Model initialized successfully.
simple_ddm_model
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 500
Parameters:
v:
Prior: Normal(mu: 0.0, sigma: 2.0)
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
The print() function gives us some basic information about our model including the number of observations the parameters in the model and their respective prior setting. We can also create a nice little graphical representation of our model...
Model Graph¶
Since HSSM creates a PyMC Model, we can can use the .graph() function, to get a graphical representation of the the model we created.
simple_ddm_model.graph()
max_shape: (500,) size: (np.int64(500),)

This is the simplest model we can build. The graph above follows plate notation, commonly used for probabilistic graphical models.
- We have our basic parameters (unobserved, white nodes), these are random variables in the model and we want to estimate them
- Our observed reaction times and choices (
SSMRandomVariable, grey node), are fixed (or conditioned on). - Rounded rectangles provide us with information about dimensionality of objects
- Rectangles with sharp edges represent deterministic, but computed quantities (not shown here, but in later models)
This notation is helpful to get a quick overview of the structure of a given model we construct.
The graph() function of course becomes a lot more interesting and useful for more complicated models!
Sample from the Model¶
We can now call the .sample() function, to get posterior samples. The main arguments you may want to change are listed in the function call below.
Importantly, multiple backends are possible. We choose the numpyro backend below,
which in turn compiles the model to a JAX function.
infer_data_simple_ddm_model = simple_ddm_model.sample(
sampler="pymc", # type of sampler to choose, 'numpyro',
# 'blackjax' of default pymc nuts sampler
cores=1, # how many cores to use
chains=2, # how many chains to run
draws=500, # number of draws from the markov chain
tune=1000, # number of burn-in samples
idata_kwargs=dict(log_likelihood=True), # return log likelihood
mp_ctx="spawn",
) # mp_ctx="forkserver")
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 1_000 tune and 500 draw iterations (2_000 + 1_000 draws total) took 12 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 1000/1000 [00:00<00:00, 3152.89it/s]
We sampled from the model, let's look at the output...
type(infer_data_simple_ddm_model)
arviz.data.inference_data.InferenceData
Errr... a closer look might be needed here!
Inference Data / What gets returned from the sampler?¶
The sampler returns an ArviZ InferenceData object.
To understand all the logic behind these objects and how they mesh with the Bayesian Workflow, we refer you to the ArviZ Documentation.
InferenceData is build on top of xarrays. The xarray documentation will help you understand in more detail how to manipulate these objects.
But let's take a quick high-level look to understand roughly what we are dealing with here!
infer_data_simple_ddm_model
-
<xarray.Dataset> Size: 36kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499 Data variables: z (chain, draw) float64 8kB 0.4699 0.499 0.4901 ... 0.486 0.4572 v (chain, draw) float64 8kB 0.5595 0.5232 0.5655 ... 0.5693 0.4741 t (chain, draw) float64 8kB 0.4846 0.5535 0.4914 ... 0.4404 0.4515 a (chain, draw) float64 8kB 1.448 1.453 1.493 ... 1.544 1.502 1.522 Attributes: created_at: 2025-09-29T19:49:47.177748+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 12.301905870437622 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 4MB Dimensions: (chain: 2, draw: 500, __obs__: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 * __obs__ (__obs__) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499 Data variables: rt,response (chain, draw, __obs__) float64 4MB -1.266 -1.822 ... -3.913 Attributes: modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 134kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499 Data variables: (12/18) energy (chain, draw) float64 8kB 1.035e+03 ... 1.034e+03 step_size_bar (chain, draw) float64 8kB 0.6405 0.6405 ... 0.6046 divergences (chain, draw) int64 8kB 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 8kB 1.667e+06 ... 1.667e+06 diverging (chain, draw) bool 1kB False False ... False False step_size (chain, draw) float64 8kB 0.5453 0.5453 ... 0.5707 ... ... acceptance_rate (chain, draw) float64 8kB 0.9491 0.9308 ... 0.8723 lp (chain, draw) float64 8kB -1.03e+03 ... -1.033e+03 reached_max_treedepth (chain, draw) bool 1kB False False ... False False perf_counter_diff (chain, draw) float64 8kB 0.003445 ... 0.001767 index_in_trajectory (chain, draw) int64 8kB -2 2 6 -1 3 ... -2 -4 3 2 2 max_energy_error (chain, draw) float64 8kB -0.8205 -0.2623 ... -0.7689 Attributes: created_at: 2025-09-29T19:49:47.275334+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 12.301905870437622 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 12kB Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2) Coordinates: * __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499 * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1 Data variables: rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 1... Attributes: created_at: 2025-09-29T19:49:47.278931+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 modeling_interface: bambi modeling_interface_version: 0.15.0
We see that in our case, infer_data_simple_ddm_model contains four basic types of data (note: this is extensible!)
posteriorlog_likelihoodsample_statsobserved_data
The posterior object contains our traces for each of the parameters in the model. The log_likelihood field contains the trial wise log-likelihoods for each sample from the posterior. The sample_stats field contains information about the sampler run. This can be important for chain diagnostics, but we will not dwell on this here. Finally we retreive our observed_data.
Basic Manipulation¶
Accessing groups and variables¶
infer_data_simple_ddm_model.posterior
<xarray.Dataset> Size: 36kB
Dimensions: (chain: 2, draw: 500)
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
z (chain, draw) float64 8kB 0.4699 0.499 0.4901 ... 0.486 0.4572
v (chain, draw) float64 8kB 0.5595 0.5232 0.5655 ... 0.5693 0.4741
t (chain, draw) float64 8kB 0.4846 0.5535 0.4914 ... 0.4404 0.4515
a (chain, draw) float64 8kB 1.448 1.453 1.493 ... 1.544 1.502 1.522
Attributes:
created_at: 2025-09-29T19:49:47.177748+00:00
arviz_version: 0.22.0
inference_library: pymc
inference_library_version: 5.25.1
sampling_time: 12.301905870437622
tuning_steps: 1000
modeling_interface: bambi
modeling_interface_version: 0.15.0infer_data_simple_ddm_model.posterior.a.head()
<xarray.DataArray 'a' (chain: 2, draw: 5)> Size: 80B
array([[1.44759672, 1.45259529, 1.49343447, 1.50284014, 1.51263448],
[1.53550489, 1.48549947, 1.49767733, 1.48435983, 1.43010851]])
Coordinates:
* chain (chain) int64 16B 0 1
* draw (draw) int64 40B 0 1 2 3 4To simply access the underlying data as a numpy.ndarray, we can use .values (as e.g. when using pandas.DataFrame objects).
type(infer_data_simple_ddm_model.posterior.a.values)
numpy.ndarray
# infer_data_simple_ddm_model.posterior.a.values
Combine chain and draw dimension¶
When operating directly on the xarray, you will often find it useful to collapse the chain and draw coordinates into a single coordinate.
Arviz makes this easy via the extract method.
idata_extracted = az.extract(infer_data_simple_ddm_model)
idata_extracted
<xarray.Dataset> Size: 56kB
Dimensions: (sample: 1000)
Coordinates:
* sample (sample) object 8kB MultiIndex
* chain (sample) int64 8kB 0 0 0 0 0 0 0 0 0 0 0 ... 1 1 1 1 1 1 1 1 1 1 1
* draw (sample) int64 8kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
z (sample) float64 8kB 0.4699 0.499 0.4901 ... 0.4855 0.486 0.4572
v (sample) float64 8kB 0.5595 0.5232 0.5655 ... 0.5022 0.5693 0.4741
t (sample) float64 8kB 0.4846 0.5535 0.4914 ... 0.5048 0.4404 0.4515
a (sample) float64 8kB 1.448 1.453 1.493 1.503 ... 1.544 1.502 1.522
Attributes:
created_at: 2025-09-29T19:49:47.177748+00:00
arviz_version: 0.22.0
inference_library: pymc
inference_library_version: 5.25.1
sampling_time: 12.301905870437622
tuning_steps: 1000
modeling_interface: bambi
modeling_interface_version: 0.15.0Since Arviz really just calls the .stack() method from xarray, here the corresponding example using the lower level xarray interface.
infer_data_simple_ddm_model.posterior.stack(sample=("chain", "draw"))
<xarray.Dataset> Size: 56kB
Dimensions: (sample: 1000)
Coordinates:
* sample (sample) object 8kB MultiIndex
* chain (sample) int64 8kB 0 0 0 0 0 0 0 0 0 0 0 ... 1 1 1 1 1 1 1 1 1 1 1
* draw (sample) int64 8kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499
Data variables:
z (sample) float64 8kB 0.4699 0.499 0.4901 ... 0.4855 0.486 0.4572
v (sample) float64 8kB 0.5595 0.5232 0.5655 ... 0.5022 0.5693 0.4741
t (sample) float64 8kB 0.4846 0.5535 0.4914 ... 0.5048 0.4404 0.4515
a (sample) float64 8kB 1.448 1.453 1.493 1.503 ... 1.544 1.502 1.522
Attributes:
created_at: 2025-09-29T19:49:47.177748+00:00
arviz_version: 0.22.0
inference_library: pymc
inference_library_version: 5.25.1
sampling_time: 12.301905870437622
tuning_steps: 1000
modeling_interface: bambi
modeling_interface_version: 0.15.0Making use of ArviZ¶
Working with the InferenceData directly, is very helpful if you want to include custom computations into your workflow.
For a basic Bayesian Workflow however, you will often find that standard functionality available through ArviZ
suffices.
Below we provide a few examples of useful Arviz outputs, which come handy for analyzing your traces (MCMC samples).
Summary table¶
Let's take a look at a summary table for our posterior.
az.summary(
infer_data_simple_ddm_model,
var_names=[var_name.name for var_name in simple_ddm_model.pymc_model.free_RVs],
)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| t | 0.490 | 0.032 | 0.431 | 0.549 | 0.001 | 0.001 | 534.0 | 564.0 | 1.00 |
| a | 1.488 | 0.039 | 1.425 | 1.571 | 0.002 | 0.001 | 556.0 | 714.0 | 1.00 |
| z | 0.491 | 0.018 | 0.457 | 0.524 | 0.001 | 0.001 | 616.0 | 528.0 | 1.00 |
| v | 0.506 | 0.048 | 0.420 | 0.598 | 0.002 | 0.001 | 650.0 | 737.0 | 1.01 |
This table returns the parameter-wise mean of our posterior and a few extra statistics.
Of these extra statistics, the one-stop shop for flagging convergence issues is the r_hat value, which
is reported in the right-most column.
To navigate this statistic, here is a rule of thumb widely used in applied Bayesian statistics.
If you find an r_hat value > 1.01, it warrants investigation.
Trace plot¶
az.plot_trace(
infer_data_simple_ddm_model, # we exclude the log_likelihood traces here
lines=[(key_, {}, param_dict_init[key_]) for key_ in param_dict_init],
)
plt.tight_layout()

The .sample() function also sets a trace attribute, on our hssm class, so instead, we could call the plot like so:
az.plot_trace(
simple_ddm_model.traces,
lines=[(key_, {}, param_dict_init[key_]) for key_ in param_dict_init],
);

In this tutorial we are most often going to use the latter way of accessing the traces, but there is no preferred option.
Let's look at a few more plots.
Forest Plot¶
The forest plot is commonly used for a quick visual check of the marginal posteriors. It is very effective for intuitive communication of results.
az.plot_forest(simple_ddm_model.traces)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Combining Chains¶
By default, chains are separated out into separate caterpillars, however
sometimes, especially if you are looking at a forest plot which includes many posterior parameters at once, you want to declutter and collapse the chains into single caterpillars.
In this case you can combine chains instead.
az.plot_forest(simple_ddm_model.traces, combined=True)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Basic Marginal Posterior Plot¶
Another way to view the marginal posteriors is provided by the plot_posterior() function. It shows the mean and by default the $94\%$ HDIs.
az.plot_posterior(simple_ddm_model.traces)
array([<Axes: title={'center': 'z'}>, <Axes: title={'center': 'v'}>,
<Axes: title={'center': 't'}>, <Axes: title={'center': 'a'}>],
dtype=object)

Especially for parameter recovery studies, you may want to include reference values for the parameters of interest.
You can do so using the ref_val argument. See the example below:
az.plot_posterior(
simple_ddm_model.traces,
ref_val=[
param_dict_init[var_name]
for var_name in simple_ddm_model.traces.posterior.data_vars
],
)
array([<Axes: title={'center': 'z'}>, <Axes: title={'center': 'v'}>,
<Axes: title={'center': 't'}>, <Axes: title={'center': 'a'}>],
dtype=object)

Since it is sometimes useful, especially for more complex cases, below an alternative approach in which we pass ref_val as a dictionary.
az.plot_posterior(
simple_ddm_model.traces,
ref_val={
"v": [{"ref_val": param_dict_init["v"]}],
"a": [{"ref_val": param_dict_init["a"]}],
"z": [{"ref_val": param_dict_init["z"]}],
"t": [{"ref_val": param_dict_init["t"]}],
},
)
array([<Axes: title={'center': 'z'}>, <Axes: title={'center': 'v'}>,
<Axes: title={'center': 't'}>, <Axes: title={'center': 'a'}>],
dtype=object)
Posterior Pair Plot¶
The posterior pair plot show us bi-variate traceplots and is useful to check for simple parameter tradeoffs that may emerge. The simplest (linear) tradeoff may be a high correlation between two parameters. This can be very helpful in diagnosing sampler issues for example. If such tradeoffs exist, one often see extremely wide marginal distributions.
In our ddm example, we see a little bit of a tradeoff between a and t, as well as between v and z, however nothing concerning.
az.plot_pair(
simple_ddm_model.traces,
kind="kde",
reference_values=param_dict_init,
marginals=True,
);

The few plot we showed here are just the beginning: ArviZ has a much broader spectrum of graphs and other convenience function available. Just check the documentation.
# Calculate the correlation matrix
posterior_correlation_matrix = np.corrcoef(
np.stack(
[idata_extracted[var_].values for var_ in idata_extracted.data_vars.variables]
)
)
num_vars = posterior_correlation_matrix.shape[0]
# Make heatmap
fig, ax = plt.subplots(1, 1)
cax = ax.imshow(posterior_correlation_matrix, cmap="coolwarm", vmin=-1, vmax=1)
fig.colorbar(cax, ax=ax)
ax.set_title("Posterior Correlation Matrix")
# Add ticks
ax.set_xticks(range(posterior_correlation_matrix.shape[0]))
ax.set_xticklabels([var_ for var_ in idata_extracted.data_vars.variables])
ax.set_yticks(range(posterior_correlation_matrix.shape[0]))
ax.set_yticklabels([var_ for var_ in idata_extracted.data_vars.variables])
# Annotate heatmap
for i in range(num_vars):
for j in range(num_vars):
ax.text(
j,
i,
f"{posterior_correlation_matrix[i, j]:.2f}",
ha="center",
va="center",
color="black",
)
plt.show()

HSSM Model based on LAN likelihood¶
With HSSM you can switch between pre-supplied models with a simple change of argument. The type of likelihood that will be accessed might change in the background for you.
Here we see an example in which the underlying likelihood is now a LAN.
We will talk more about different types of likelihood functions and backends later in the tutorial. For now just keep the following in mind:
There are three types of likelihoods
analyticapprox_differentiableblackbox
To check which type is used in your HSSM model simple type:
simple_ddm_model.loglik_kind
'analytical'
Ah... we were using an analytical likelihood with the DDM model in the last section.
Now let's see something different!
Simulating Angle Data¶
Again, let us simulate a simple dataset. This time we will use the angle model (passed via the model argument to the simulator() function).
This model is distinguished from the basic ddm model by an additional theta parameter which specifies the angle with which the decision boundaries collapse over time.
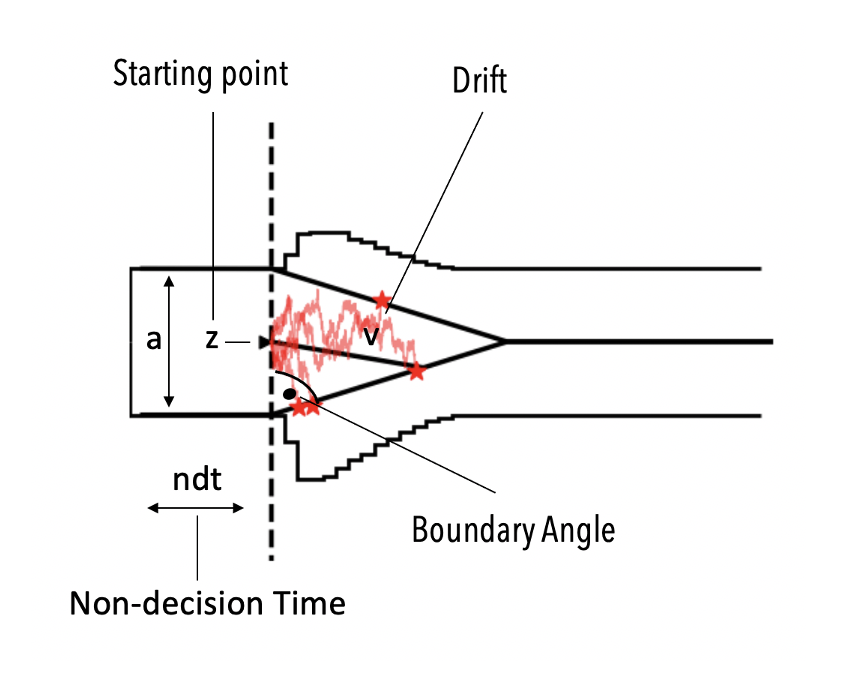
DDMs with collapsing bounds have been of significant interest in the theoretical literature, but applications were rare due to a lack of analytical likelihoods. HSSM facilitates inference with such models via the our approx_differentiable likelihoods. HSSM ships with a few predefined models based on LANs, but really we don't want to overemphasize those. They reflect the research interest of our and adjacent labs to a great extend.
Instead, we encourage the community to contribute to this model reservoir (more on this later).
# Simulate angle data
v_angle_true = 0.5
a_angle_true = 1.5
z_angle_true = 0.5
t_angle_true = 0.2
theta_angle_true = 0.2
param_dict_angle = dict(v=0.5, a=1.5, z=0.5, t=0.2, theta=0.2)
lines_list_angle = [(key_, {}, param_dict_angle[key_]) for key_ in param_dict_angle]
dataset_angle = hssm.simulate_data(model="angle", theta=param_dict_angle, size=1000)
We pass a single additional argument to our HSSM class and set model='angle'.
model_angle = hssm.HSSM(data=dataset_angle, model="angle")
model_angle
Model initialized successfully.
Hierarchical Sequential Sampling Model
Model: angle
Response variable: rt,response
Likelihood: approx_differentiable
Observations: 1000
Parameters:
v:
Prior: Uniform(lower: -3.0, upper: 3.0)
Explicit bounds: (-3.0, 3.0)
a:
Prior: Uniform(lower: 0.3, upper: 3.0)
Explicit bounds: (0.3, 3.0)
z:
Prior: Uniform(lower: 0.1, upper: 0.9)
Explicit bounds: (0.1, 0.9)
t:
Prior: Uniform(lower: 0.001, upper: 2.0)
Explicit bounds: (0.001, 2.0)
theta:
Prior: Uniform(lower: -0.1, upper: 1.3)
Explicit bounds: (-0.1, 1.3)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
The model graph now show us an additional parameter theta!
model_angle.graph()
max_shape: (1000,) size: (np.int64(1000),)

Let's check the type of likelihood that is used under the hood ...
model_angle.loglik_kind
'approx_differentiable'
Ok so here we rely on a likelihood of the approx_differentiable kind.
As discussed, with the initial set of pre-supplied likelihoods, this implies that we are using a LAN in the background.
jax.config.update("jax_enable_x64", False)
infer_data_angle = model_angle.sample(
sampler="numpyro",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
# mp_ctx="spawn",
)
Using default initvals.
sample: 100%|██████████| 1000/1000 [00:10<00:00, 93.30it/s, 15 steps of size 2.74e-01. acc. prob=0.94] sample: 100%|██████████| 1000/1000 [00:09<00:00, 104.06it/s, 23 steps of size 2.56e-01. acc. prob=0.95] We recommend running at least 4 chains for robust computation of convergence diagnostics
az.plot_trace(model_angle.traces, lines=lines_list_angle)
plt.tight_layout()

Choosing Priors¶
HSSM allows you to specify priors quite freely. If you used HDDM previously, you may feel relieved to read that your hands are now untied!
With HSSM we have multiple routes to priors. But let's first consider a special case:
Fixing a parameter to a given value¶
Assume that instead of fitting all parameters of the DDM,
we instead want to fit only the v (drift) parameter, setting all other parameters to fixed scalar values.
HSSM makes this extremely easy!
param_dict_init
{'v': 0.5, 'a': 1.5, 'z': 0.5, 't': 0.5}
ddm_model_only_v = hssm.HSSM(
data=dataset,
model="ddm",
a=param_dict_init["a"],
t=param_dict_init["t"],
z=param_dict_init["z"],
)
Model initialized successfully.
Since we fix all but one parameter, we therefore estimate only one parameter. This should be reflected in our model graph, where we expect only one free random variable v:
ddm_model_only_v.graph()
max_shape: (500,) size: (np.int64(500),)

ddm_model_only_v.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 26 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
-
<xarray.Dataset> Size: 12kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 7 ... 493 494 495 496 497 498 499 Data variables: v (chain, draw) float64 8kB 0.5138 0.4859 0.4723 ... 0.5077 0.5747 Attributes: created_at: 2025-09-29T19:50:45.261410+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 26.393324613571167 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 134kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499 Data variables: (12/18) energy (chain, draw) float64 8kB 1.025e+03 ... 1.027e+03 step_size_bar (chain, draw) float64 8kB 1.261 1.261 ... 1.361 1.361 divergences (chain, draw) int64 8kB 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 8kB 1.667e+06 ... 1.667e+06 diverging (chain, draw) bool 1kB False False ... False False step_size (chain, draw) float64 8kB 1.815 1.815 ... 1.841 1.841 ... ... acceptance_rate (chain, draw) float64 8kB 1.0 0.9954 ... 0.5455 lp (chain, draw) float64 8kB -1.024e+03 ... -1.027e+03 reached_max_treedepth (chain, draw) bool 1kB False False ... False False perf_counter_diff (chain, draw) float64 8kB 5.554e-05 ... 8.546e-05 index_in_trajectory (chain, draw) int64 8kB -1 -2 -1 1 -1 ... 1 -1 -1 -1 max_energy_error (chain, draw) float64 8kB -0.1867 -0.02249 ... 0.8843 Attributes: created_at: 2025-09-29T19:50:45.278212+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 26.393324613571167 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 12kB Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2) Coordinates: * __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499 * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1 Data variables: rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 1... Attributes: created_at: 2025-09-29T19:50:45.280985+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 modeling_interface: bambi modeling_interface_version: 0.15.0
az.plot_trace(
ddm_model_only_v.traces.posterior, lines=[("v", {}, param_dict_init["v"])]
);

Instead of the trace on the right, a useful alternative / complement is the rank plot. As a rule of thumb, if the rank plots within chains look uniformly distributed, then our chains generally exhibit good mixing.
az.plot_trace(ddm_model_only_v.traces, kind="rank_bars")
array([[<Axes: title={'center': 'v'}>,
<Axes: title={'center': 'v'}, xlabel='Rank (all chains)', ylabel='Chain'>]],
dtype=object)

Named priors¶
We can choose any PyMC Distribution to specify a prior for a given parameter.
Even better, if natural parameter bounds are provided, HSSM automatically truncates the prior distribution so that it respect these bounds.
Below is an example in which we specify a Normal prior on the v parameter of the DDM.
We choose a ridiculously low $\sigma$ value, to illustrate it's regularizing effect on the parameter (just so we see a difference and you are convinced that something changed).
model_normal = hssm.HSSM(
data=dataset,
include=[
{
"name": "v",
"prior": {"name": "Normal", "mu": 0, "sigma": 0.01},
}
],
)
Model initialized successfully.
model_normal
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 500
Parameters:
v:
Prior: Normal(mu: 0.0, sigma: 0.01)
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
infer_data_normal = model_normal.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
idata_kwargs=dict(log_likelihood=False), # no need to return likelihoods here
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 30 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
az.plot_trace(
model_normal.traces,
lines=[(key_, {}, param_dict_init[key_]) for key_ in param_dict_init],
)
array([[<Axes: title={'center': 'v'}>, <Axes: title={'center': 'v'}>],
[<Axes: title={'center': 'a'}>, <Axes: title={'center': 'a'}>],
[<Axes: title={'center': 'z'}>, <Axes: title={'center': 'z'}>],
[<Axes: title={'center': 't'}>, <Axes: title={'center': 't'}>]],
dtype=object)

Observe how we reused our previous dataset with underlying parameters
v = 0.5a = 1.5z = 0.5t = 0.2
In contrast to our previous sampler round, in which we used Uniform priors, here the v estimate is shrunk severley towared $0$ and the t and z parameter estimates are very biased to make up for this distortion. Also, overall we see a lot of divergences now, which is a sign of poor sampler performance.
HSSM Model with Regression¶

Crucial to the scope of HSSM is the ability to link parameters with trial-by-trial covariates via (hierarchical, but more on this later) general linear models.
In this section we explore how HSSM deals with these models. No big surprise here... it's simple!
Case 1: One parameter is a Regression Target¶
Simulating Data¶
Let's first simulate some data, where the trial-by-trial parameters of the v parameter in our model are driven by a simple linear regression model.
The regression model is driven by two (random) covariates x and y, respectively with coefficients of $0.8$ and $0.3$ which are also simulated below.
We set the intercept to $0.3$.
The rest of the parameters are fixed to single values as before.
# Set up trial by trial parameters
v_intercept = 0.3
x = np.random.uniform(-1, 1, size=1000)
v_x = 0.8
y = np.random.uniform(-1, 1, size=1000)
v_y = 0.3
v_reg_v = v_intercept + (v_x * x) + (v_y * y)
# rest
a_reg_v = 1.5
z_reg_v = 0.5
t_reg_v = 0.1
param_dict_reg_v = dict(
a=1.5, z=0.5, t=0.1, v=v_reg_v, v_x=v_x, v_y=v_y, v_Intercept=v_intercept, theta=0.0
)
# base dataset
dataset_reg_v = hssm.simulate_data(model="ddm", theta=param_dict_reg_v, size=1)
# Adding covariates into the datsaframe
dataset_reg_v["x"] = x
dataset_reg_v["y"] = y
Basic Model¶
We now create the HSSM model.
Notice how we set the include argument. The include argument expects a list of dictionaries, one dictionary for each parameter to be specified via a regression model.
Four keys are expected to be set:
- The
nameof the parameter, - Potentially a
priorfor each of the regression level parameters ($\beta$'s), - The regression
formula - A
linkfunction.
The regression formula follows the syntax in the formulae python package (as used by the Bambi package for building Bayesian Hierarchical Regression Models.
Bambi forms the main model-construction backend of HSSM.
model_reg_v_simple = hssm.HSSM(
data=dataset_reg_v, include=[{"name": "v", "formula": "v ~ 1 + x + y"}]
)
Model initialized successfully.
model_reg_v_simple
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
Param class¶
As illustrated below, there is an alternative way of specifying the parameter specific data via the Param class.
model_reg_v_simple_new = hssm.HSSM(
data=dataset_reg_v, include=[hssm.Param(name="v", formula="v ~ 1 + x + y")]
)
Model initialized successfully.
model_reg_v_simple_new
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
model_reg_v_simple.graph()
max_shape: (1000,) size: (np.int64(1000),)

print(model_reg_v_simple)
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Normal(mu: 2.0, sigma: 3.0)
v_x ~ Normal(mu: 0.0, sigma: 0.25)
v_y ~ Normal(mu: 0.0, sigma: 0.25)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
Custom Model¶
These were the defaults, with a little extra labor, we can e.g. customize the choice of priors for each parameter in the model.
model_reg_v = hssm.HSSM(
data=dataset_reg_v,
include=[
{
"name": "v",
"prior": {
"Intercept": {"name": "Uniform", "lower": -3.0, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v
Hierarchical Sequential Sampling Model
Model: ddm
Response variable: rt,response
Likelihood: analytical
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Uniform(lower: -3.0, upper: 3.0)
v_x ~ Uniform(lower: -1.0, upper: 1.0)
v_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (-inf, inf)
a:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
z:
Prior: Uniform(lower: 0.0, upper: 1.0)
Explicit bounds: (0.0, 1.0)
t:
Prior: HalfNormal(sigma: 2.0)
Explicit bounds: (0.0, inf)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
Notice how v is now set as a regression.
infer_data_reg_v = model_reg_v.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [t, a, z, v_Intercept, v_x, v_y]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 39 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 1000/1000 [00:00<00:00, 2845.41it/s]
infer_data_reg_v
-
<xarray.Dataset> Size: 52kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 Data variables: v_x (chain, draw) float64 8kB 0.9023 0.8891 0.7967 ... 0.913 0.875 v_Intercept (chain, draw) float64 8kB 0.3388 0.2968 ... 0.3058 0.2966 z (chain, draw) float64 8kB 0.5182 0.5146 0.5165 ... 0.517 0.5136 v_y (chain, draw) float64 8kB 0.3807 0.4119 0.3528 ... 0.4372 0.326 a (chain, draw) float64 8kB 1.469 1.488 1.447 ... 1.45 1.488 t (chain, draw) float64 8kB 0.1158 0.1225 ... 0.1299 0.09166 Attributes: created_at: 2025-09-29T19:52:06.564238+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 38.77959203720093 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 8MB Dimensions: (chain: 2, draw: 500, __obs__: 1000) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 * __obs__ (__obs__) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 Data variables: rt,response (chain, draw, __obs__) float64 8MB -5.873 -0.9084 ... -3.016 Attributes: modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 134kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499 Data variables: (12/18) energy (chain, draw) float64 8kB 1.949e+03 ... 1.951e+03 step_size_bar (chain, draw) float64 8kB 0.5283 0.5283 ... 0.6212 divergences (chain, draw) int64 8kB 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 8kB 1.667e+06 ... 1.667e+06 diverging (chain, draw) bool 1kB False False ... False False step_size (chain, draw) float64 8kB 0.4589 0.4589 ... 0.5872 ... ... acceptance_rate (chain, draw) float64 8kB 1.0 1.0 ... 0.8678 0.5956 lp (chain, draw) float64 8kB -1.946e+03 ... -1.946e+03 reached_max_treedepth (chain, draw) bool 1kB False False ... False False perf_counter_diff (chain, draw) float64 8kB 0.006973 ... 0.006783 index_in_trajectory (chain, draw) int64 8kB -6 2 -6 3 -1 ... -1 1 -1 -2 max_energy_error (chain, draw) float64 8kB -1.105 -0.4064 ... 1.978 Attributes: created_at: 2025-09-29T19:52:06.577971+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 38.77959203720093 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 24kB Dimensions: (__obs__: 1000, rt,response_extra_dim_0: 2) Coordinates: * __obs__ (__obs__) int64 8kB 0 1 2 3 4 ... 996 997 998 999 * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1 Data variables: rt,response (__obs__, rt,response_extra_dim_0) float64 16kB ... Attributes: created_at: 2025-09-29T19:52:06.580600+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 modeling_interface: bambi modeling_interface_version: 0.15.0
# az.plot_forest(model_reg_v.traces)
az.plot_trace(
model_reg_v.traces,
var_names=["~v"],
lines=[(key_, {}, param_dict_reg_v[key_]) for key_ in param_dict_reg_v],
)
array([[<Axes: title={'center': 'v_x'}>, <Axes: title={'center': 'v_x'}>],
[<Axes: title={'center': 'v_Intercept'}>,
<Axes: title={'center': 'v_Intercept'}>],
[<Axes: title={'center': 'z'}>, <Axes: title={'center': 'z'}>],
[<Axes: title={'center': 'v_y'}>, <Axes: title={'center': 'v_y'}>],
[<Axes: title={'center': 'a'}>, <Axes: title={'center': 'a'}>],
[<Axes: title={'center': 't'}>, <Axes: title={'center': 't'}>]],
dtype=object)

az.plot_trace(
model_reg_v.traces,
var_names=["~v"],
lines=[(key_, {}, param_dict_reg_v[key_]) for key_ in param_dict_reg_v],
)
plt.tight_layout()

# Looks like parameter recovery was successful
az.summary(model_reg_v.traces, var_names=["~v"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| v_x | 0.869 | 0.045 | 0.785 | 0.952 | 0.002 | 0.002 | 602.0 | 302.0 | 1.0 |
| v_Intercept | 0.308 | 0.035 | 0.249 | 0.377 | 0.001 | 0.001 | 769.0 | 664.0 | 1.0 |
| z | 0.510 | 0.013 | 0.487 | 0.534 | 0.000 | 0.000 | 679.0 | 496.0 | 1.0 |
| v_y | 0.379 | 0.046 | 0.301 | 0.472 | 0.001 | 0.002 | 1203.0 | 726.0 | 1.0 |
| a | 1.475 | 0.026 | 1.426 | 1.520 | 0.001 | 0.001 | 713.0 | 719.0 | 1.0 |
| t | 0.114 | 0.017 | 0.081 | 0.146 | 0.001 | 0.001 | 841.0 | 739.0 | 1.0 |
Case 2: One parameter is a Regression (LAN)¶
We can do the same thing with the angle model.
Note:
Our dataset was generated from the basic DDM here, so since the DDM assumes stable bounds, we expect the theta (angle of linear collapse) parameter to be recovered as close to $0$.
model_reg_v_angle = hssm.HSSM(
data=dataset_reg_v,
model="angle",
include=[
{
"name": "v",
"prior": {
"Intercept": {
"name": "Uniform",
"lower": -3.0,
"upper": 3.0,
},
"x": {
"name": "Uniform",
"lower": -1.0,
"upper": 1.0,
},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_angle.graph()
max_shape: (1000,) size: (np.int64(1000),)

trace_reg_v_angle = model_reg_v_angle.sample(
sampler="pymc",
chains=1,
cores=1,
draws=1000,
tune=500,
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (1 chains in 1 job) NUTS: [a, z, theta, t, v_Intercept, v_x, v_y]
Output()
Sampling 1 chain for 500 tune and 1_000 draw iterations (500 + 1_000 draws total) took 38 seconds. Only one chain was sampled, this makes it impossible to run some convergence checks 100%|██████████| 1000/1000 [00:00<00:00, 1957.82it/s]
az.plot_trace(
model_reg_v_angle.traces,
var_names=["~v"],
lines=[(key_, {}, param_dict_reg_v[key_]) for key_ in param_dict_reg_v],
)
plt.tight_layout()

Great! theta is recovered correctly, on top of that, we have reasonable recovery for all other parameters!
Case 3: Multiple Parameters are Regression Targets (LAN)¶
Let's get a bit more ambitious. We may, for example, want to try a regression on a few of our basic model parameters at once. Below we show an example where we model both the a and the v parameters with a regression.
NOTE:
In our dataset of this section, only v is actually driven by a trial-by-trial regression, so we expect the regression coefficients for a to hover around $0$ in our posterior.
# Instantiate our hssm model
from copy import deepcopy
param_dict_reg_v_a = deepcopy(param_dict_reg_v)
param_dict_reg_v_a["a_Intercept"] = param_dict_reg_v_a["a"]
param_dict_reg_v_a["a_x"] = 0
param_dict_reg_v_a["a_y"] = 0
hssm_reg_v_a_angle = hssm.HSSM(
data=dataset_reg_v,
model="angle",
include=[
{
"name": "v",
"prior": {
"Intercept": {"name": "Uniform", "lower": -3.0, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "v ~ 1 + x + y",
},
{
"name": "a",
"prior": {
"Intercept": {"name": "Uniform", "lower": 0.5, "upper": 3.0},
"x": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
"y": {"name": "Uniform", "lower": -1.0, "upper": 1.0},
},
"formula": "a ~ 1 + x + y",
},
],
)
Model initialized successfully.
hssm_reg_v_a_angle
Hierarchical Sequential Sampling Model
Model: angle
Response variable: rt,response
Likelihood: approx_differentiable
Observations: 1000
Parameters:
v:
Formula: v ~ 1 + x + y
Priors:
v_Intercept ~ Uniform(lower: -3.0, upper: 3.0)
v_x ~ Uniform(lower: -1.0, upper: 1.0)
v_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (-3.0, 3.0)
a:
Formula: a ~ 1 + x + y
Priors:
a_Intercept ~ Uniform(lower: 0.5, upper: 3.0)
a_x ~ Uniform(lower: -1.0, upper: 1.0)
a_y ~ Uniform(lower: -1.0, upper: 1.0)
Link: identity
Explicit bounds: (0.3, 3.0)
z:
Prior: Uniform(lower: 0.1, upper: 0.9)
Explicit bounds: (0.1, 0.9)
t:
Prior: Uniform(lower: 0.001, upper: 2.0)
Explicit bounds: (0.001, 2.0)
theta:
Prior: Uniform(lower: -0.1, upper: 1.3)
Explicit bounds: (-0.1, 1.3)
Lapse probability: 0.05
Lapse distribution: Uniform(lower: 0.0, upper: 20.0)
hssm_reg_v_a_angle.graph()
max_shape: (1000,) size: (np.int64(1000),)

infer_data_reg_v_a = hssm_reg_v_a_angle.sample(
sampler="pymc",
chains=2,
cores=1,
draws=1000,
tune=1000,
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [z, theta, t, v_Intercept, v_x, v_y, a_Intercept, a_x, a_y]
Output()
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 116 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 2000/2000 [00:00<00:00, 2143.22it/s]
az.summary(
infer_data_reg_v_a, var_names=["~a", "~v"]
) # , var_names=["~rt,response_a"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| v_x | 0.865 | 0.048 | 0.775 | 0.953 | 0.001 | 0.001 | 1484.0 | 556.0 | 1.00 |
| a_y | 0.100 | 0.039 | 0.030 | 0.175 | 0.001 | 0.001 | 1949.0 | 1487.0 | 1.00 |
| v_Intercept | 0.291 | 0.034 | 0.225 | 0.349 | 0.001 | 0.001 | 1733.0 | 1351.0 | 1.00 |
| z | 0.523 | 0.013 | 0.500 | 0.547 | 0.000 | 0.000 | 1692.0 | 1590.0 | 1.00 |
| a_x | 0.039 | 0.043 | -0.040 | 0.119 | 0.001 | 0.001 | 1828.0 | 1298.0 | 1.00 |
| v_y | 0.394 | 0.048 | 0.303 | 0.484 | 0.001 | 0.001 | 1767.0 | 1204.0 | 1.00 |
| a_Intercept | 1.591 | 0.057 | 1.483 | 1.699 | 0.003 | 0.002 | 559.0 | 394.0 | 1.01 |
| theta | 0.073 | 0.025 | 0.027 | 0.120 | 0.001 | 0.001 | 692.0 | 612.0 | 1.01 |
| t | 0.075 | 0.027 | 0.018 | 0.120 | 0.001 | 0.001 | 545.0 | 257.0 | 1.00 |
az.plot_trace(
hssm_reg_v_a_angle.traces,
var_names=["~v", "~a"],
lines=[(key_, {}, param_dict_reg_v_a[key_]) for key_ in param_dict_reg_v_a],
)
plt.tight_layout()

We successfully recover our regression betas for a! Moreover, no warning signs concerning our chains.
Case 4: Categorical covariates¶
# Set up trial by trial parameters
x = np.random.choice(4, size=1000).astype(int)
x_offset = np.array([0, 1, -0.5, 0.75])
y = np.random.uniform(-1, 1, size=1000)
v_y = 0.3
v_reg_v = 0 + (v_y * y) + x_offset[x]
# rest
a_reg_v = 1.5
z_reg_v = 0.5
t_reg_v = 0.1
# base dataset
dataset_reg_v_cat = hssm.simulate_data(
model="ddm", theta=dict(v=v_reg_v, a=a_reg_v, z=z_reg_v, t=t_reg_v), size=1
)
# Adding covariates into the datsaframe
dataset_reg_v_cat["x"] = x
dataset_reg_v_cat["y"] = y
model_reg_v_cat = hssm.HSSM(
data=dataset_reg_v_cat,
model="angle",
include=[
{
"name": "v",
"formula": "v ~ 0 + C(x) + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_cat.graph()
max_shape: (1000,) size: (np.int64(1000),)

infer_data_reg_v_cat = model_reg_v_cat.sample(
sampler="pymc",
chains=2,
cores=1,
draws=1000,
tune=500,
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [a, z, theta, t, v_C(x), v_y]
Output()
Sampling 2 chains for 500 tune and 1_000 draw iterations (1_000 + 2_000 draws total) took 61 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 2000/2000 [00:00<00:00, 2094.22it/s]
az.plot_forest(infer_data_reg_v_cat, var_names=["~v"])
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Hierarchical Inference¶
Let's try to fit a hierarchical model now. We will simulate a dataset with $15$ participants, with $200$ observations / trials for each participant.
We define a group mean mean_v and a group standard deviation sd_v for the intercept parameter of the regression on v, which we sample from a corresponding normal distribution for each participant.
Simulate Data¶
# Make some hierarchical data
n_participants = 15 # number of participants
n_trials = 200 # number of trials per participant
sd_v = 0.5 # sd for v-intercept
mean_v = 0.5 # mean for v-intercept
data_list = []
for i in range(n_participants):
# Make parameters for participant i
v_intercept_hier = np.random.normal(mean_v, sd_v, size=1)
x = np.random.uniform(-1, 1, size=n_trials)
v_x_hier = 0.8
y = np.random.uniform(-1, 1, size=n_trials)
v_y_hier = 0.3
v_hier = v_intercept_hier + (v_x_hier * x) + (v_y_hier * y)
a_hier = 1.5
t_hier = 0.5
z_hier = 0.5
# true_values = np.column_stack(
# [v, np.repeat([[1.5, 0.5, 0.5, 0.0]], axis=0, repeats=n_trials)]
# )
data_tmp = hssm.simulate_data(
model="ddm", theta=dict(v=v_hier, a=a_hier, z=z_hier, t=t_hier), size=1
)
data_tmp["participant_id"] = i
data_tmp["x"] = x
data_tmp["y"] = y
data_list.append(data_tmp)
# Make single dataframe out of participant-wise datasets
dataset_reg_v_hier = pd.concat(data_list)
dataset_reg_v_hier
| rt | response | participant_id | x | y | |
|---|---|---|---|---|---|
| 0 | 1.117741 | 1.0 | 0 | -0.535751 | 0.573336 |
| 1 | 2.871194 | 1.0 | 0 | -0.158811 | 0.024659 |
| 2 | 4.013333 | 1.0 | 0 | -0.556658 | 0.021410 |
| 3 | 1.424530 | -1.0 | 0 | -0.610495 | -0.315694 |
| 4 | 0.753883 | 1.0 | 0 | 0.499722 | 0.272538 |
| ... | ... | ... | ... | ... | ... |
| 195 | 1.164056 | 1.0 | 14 | -0.918860 | 0.234293 |
| 196 | 2.720412 | 1.0 | 14 | -0.899047 | -0.707518 |
| 197 | 1.787280 | 1.0 | 14 | 0.282337 | 0.789865 |
| 198 | 0.847754 | 1.0 | 14 | 0.152510 | -0.697267 |
| 199 | 0.920196 | 1.0 | 14 | -0.340144 | 0.562373 |
3000 rows × 5 columns
We can now define our HSSM model.
We specify the regression as v ~ 1 + (1|participant_id) + x + y.
(1|participant_id) tells the model to create a participant-wise offset for the intercept parameter. The rest of the regression $\beta$'s is fit globally.
As an R user you may recognize this syntax from the lmer package.
Our Bambi backend is essentially a Bayesian version of lmer, quite like the BRMS package in R, which operates on top of STAN.
As a previous HDDM user, you may recognize that now proper mixed-effect models are viable!
You should be able to handle between and within participant effects naturally now!
Basic Hierarchical Model¶
model_reg_v_angle_hier = hssm.HSSM(
data=dataset_reg_v_hier,
model="angle",
noncentered=True,
include=[
{
"name": "v",
"prior": {
"Intercept": {
"name": "Normal",
"mu": 0.0,
"sigma": 0.5,
},
"x": {"name": "Normal", "mu": 0.0, "sigma": 0.5},
"y": {"name": "Normal", "mu": 0.0, "sigma": 0.5},
},
"formula": "v ~ 1 + (1|participant_id) + x + y",
"link": "identity",
}
],
)
Model initialized successfully.
model_reg_v_angle_hier.graph()
max_shape: (3000,) size: (np.int64(3000),)

jax.config.update("jax_enable_x64", False)
model_reg_v_angle_hier.sample(
sampler="pymc",
chains=2,
cores=2,
draws=500,
tune=500,
mp_ctx="spawn",
)
Using default initvals. Parallel sampling might not work with `jax` backend and the PyMC NUTS sampler on some platforms. Please consider using `nuts_numpyro` or `nuts_blackjax` sampler if that is a problem.
Initializing NUTS using adapt_diag... Multiprocess sampling (2 chains in 2 jobs) NUTS: [a, z, theta, t, v_Intercept, v_x, v_y, v_1|participant_id_sigma, v_1|participant_id_offset]
Output()
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 580 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details 100%|██████████| 1000/1000 [00:01<00:00, 931.69it/s]
-
<xarray.Dataset> Size: 308kB Dimensions: (chain: 2, draw: 500, v_1|participant_id__factor_dim: 15) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 ... 496 497 498 499 * v_1|participant_id__factor_dim (v_1|participant_id__factor_dim) <U2 120B ... Data variables: v_x (chain, draw) float64 8kB 0.8682 ... 0.8462 v_Intercept (chain, draw) float64 8kB 0.6753 ... 0.4235 z (chain, draw) float64 8kB 0.4833 ... 0.4874 theta (chain, draw) float64 8kB 0.0119 ... 0.05599 v_1|participant_id_sigma (chain, draw) float64 8kB 0.4595 ... 0.3857 v_y (chain, draw) float64 8kB 0.2697 ... 0.2698 v_1|participant_id (chain, draw, v_1|participant_id__factor_dim) float64 120kB ... a (chain, draw) float64 8kB 1.471 ... 1.547 t (chain, draw) float64 8kB 0.5005 ... 0.4801 v_1|participant_id_offset (chain, draw, v_1|participant_id__factor_dim) float64 120kB ... Attributes: created_at: 2025-09-29T20:05:48.538765+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 579.8671550750732 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 24MB Dimensions: (chain: 2, draw: 500, __obs__: 3000) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 * __obs__ (__obs__) int64 24kB 0 1 2 3 4 5 ... 2995 2996 2997 2998 2999 Data variables: rt,response (chain, draw, __obs__) float64 24MB -1.022 -1.886 ... -0.3678 Attributes: modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 134kB Dimensions: (chain: 2, draw: 500) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499 Data variables: (12/18) energy (chain, draw) float64 8kB 5.188e+03 ... 5.176e+03 step_size_bar (chain, draw) float64 8kB 0.1623 0.1623 ... 0.1717 divergences (chain, draw) int64 8kB 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 8kB 1.668e+06 ... 1.668e+06 diverging (chain, draw) bool 1kB False False ... False False step_size (chain, draw) float64 8kB 0.2192 0.2192 ... 0.1931 ... ... acceptance_rate (chain, draw) float64 8kB 0.9118 0.7445 ... 0.7873 lp (chain, draw) float64 8kB -5.173e+03 ... -5.163e+03 reached_max_treedepth (chain, draw) bool 1kB False False ... False False perf_counter_diff (chain, draw) float64 8kB 0.5618 0.3479 ... 0.2888 index_in_trajectory (chain, draw) int64 8kB 13 -2 5 -24 28 ... 4 10 31 16 max_energy_error (chain, draw) float64 8kB -0.5562 0.5962 ... 0.8798 Attributes: created_at: 2025-09-29T20:05:48.566663+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 579.8671550750732 tuning_steps: 500 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 72kB Dimensions: (__obs__: 3000, rt,response_extra_dim_0: 2) Coordinates: * __obs__ (__obs__) int64 24kB 0 1 2 3 ... 2997 2998 2999 * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1 Data variables: rt,response (__obs__, rt,response_extra_dim_0) float64 48kB ... Attributes: created_at: 2025-09-29T20:05:48.570621+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 modeling_interface: bambi modeling_interface_version: 0.15.0
Let's look at the posteriors!
az.plot_forest(model_reg_v_angle_hier.traces, var_names=["~v", "~a"], combined=False)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Model Comparison¶
Fitting single models is all well and good. We are however, often interested in comparing how well a few different models account for the same data.
Through ArviZ, we have out of the box access to modern Bayesian Model Comparison. We will keep it simple here, just to illustrate the basic idea.
Scenario¶
The following scenario is explored.
First we generate data from a ddm model with fixed parameters, specifically we set the a parameter to $1.5$.
We then define two HSSM models:
- A model which allows fitting all but the
aparameter, which is fixed to $1.0$ (wrong) - A model which allows fitting all but the
aparameter, which is fixed to $1.5$ (correct)
We then use the ArviZ's compare() function, to perform model comparison via elpd_loo.
Data Simulation¶
# Parameters
param_dict_mod_comp = dict(v=0.5, a=1.5, z=0.5, t=0.2)
# Simulation
dataset_model_comp = hssm.simulate_data(
model="ddm", theta=param_dict_mod_comp, size=500
)
print(dataset_model_comp)
rt response 0 0.947397 1.0 1 0.859091 1.0 2 1.819618 1.0 3 2.348086 -1.0 4 1.360105 1.0 .. ... ... 495 1.980245 1.0 496 2.088078 1.0 497 0.558926 1.0 498 0.595095 1.0 499 2.158128 1.0 [500 rows x 2 columns]
Defining the Models¶
# 'wrong' model
model_model_comp_1 = hssm.HSSM(
data=dataset_model_comp,
model="angle",
a=1.0,
)
Model initialized successfully.
# 'correct' model
model_model_comp_2 = hssm.HSSM(
data=dataset_model_comp,
model="angle",
a=1.5,
)
Model initialized successfully.
# 'wrong' model ddm
model_model_comp_3 = hssm.HSSM(
data=dataset_model_comp,
model="ddm",
a=1.0,
)
Model initialized successfully.
infer_data_model_comp_1 = model_model_comp_1.sample(
sampler="pymc",
cores=1,
chains=2,
draws=1000,
tune=1000,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [z, theta, t, v]
Output()
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 86 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 2000/2000 [00:01<00:00, 1367.80it/s]
infer_data_model_comp_2 = model_model_comp_2.sample(
sampler="pymc",
cores=1,
chains=2,
draws=1000,
tune=1000,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [z, theta, t, v]
Output()
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 66 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 2000/2000 [00:01<00:00, 1432.74it/s]
infer_data_model_comp_3 = model_model_comp_3.sample(
sampler="pymc",
cores=1,
chains=2,
draws=1000,
tune=1000,
idata_kwargs=dict(
log_likelihood=True
), # model comparison metrics usually need this!
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, z, v]
Output()
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 9 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics 100%|██████████| 2000/2000 [00:00<00:00, 5398.52it/s]
Compare¶
compare_data = az.compare(
{
"a_fixed_1(wrong)": model_model_comp_1.traces,
"a_fixed_1.5(correct)": model_model_comp_2.traces,
"a_fixed_1_ddm(wrong)": model_model_comp_3.traces,
}
)
compare_data
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| a_fixed_1.5(correct) | 0 | -991.190525 | 3.971025 | 0.000000 | 1.000000e+00 | 24.882089 | 0.000000 | False | log |
| a_fixed_1(wrong) | 1 | -1058.022613 | 5.342018 | 66.832088 | 0.000000e+00 | 30.377535 | 11.145312 | True | log |
| a_fixed_1_ddm(wrong) | 2 | -1135.806276 | 4.812125 | 144.615751 | 5.314671e-10 | 35.463456 | 17.204704 | True | log |
Notice how the posterior weight on the correct model is close to (or equal to ) $1$ here.
In other words model comparison points us to the correct model with
a very high degree of certainty here!
We can also use the .plot_compare() function to illustrate the model comparison visually.
az.plot_compare(compare_data)
<Axes: title={'center': 'Model comparison\nhigher is better'}, xlabel='elpd_loo (log)', ylabel='ranked models'>

Using the forest plot we can take a look at what goes wrong for the "wrong" model.
To make up for the mistplaced setting of the a parameter, the posterior seems to compensate by
mis-estimating the other parameters.
az.plot_forest(
[model_model_comp_1.traces, model_model_comp_2.traces, model_model_comp_3.traces],
model_names=["a_fixed_1(wrong)", "a_fixed_1.5(correct)", "a_fixed_1(wrong)_ddm"],
)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Closer look!¶

We have seen a few examples of HSSM models at this point. Add a model via a string, maybe toy a bit with with the priors and set regression functions for a given parameter. Turn it hierarchical... Here we begin to peak a bit under the hood.
After all, we want to encourage you to contribute models to the package yourself.
Let's remind ourself of the model_config dictionaries that define model properties for us. Again let's start with the DDM.
hssm.config.default_model_config["ddm"].keys()
dict_keys(['response', 'list_params', 'choices', 'description', 'likelihoods'])
The dictionary has a few high level keys.
responselist_paramsdescriptionlikelihoods
Let us take a look at the available likelihoods:
hssm.config.default_model_config["ddm"]["likelihoods"]
{'analytical': {'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None},
'approx_differentiable': {'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None},
'blackbox': {'loglik': <function hssm.likelihoods.blackbox.hddm_to_hssm.<locals>.outer(data: numpy.ndarray, *args, **kwargs)>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}}
For the DDM we have available all three types of likelihoods that HSSM deals with:
analyticalapprox_differentiableblackbox
Let's expand the dictionary contents more:
hssm.config.default_model_config["ddm"]["likelihoods"]["analytical"]
{'loglik': <function hssm.likelihoods.analytical.logp_ddm(data: numpy.ndarray, v: float, a: float, z: float, t: float, err: float = 1e-15, k_terms: int = 20, epsilon: float = 1e-15) -> numpy.ndarray>,
'backend': None,
'bounds': {'v': (-inf, inf),
'a': (0.0, inf),
'z': (0.0, 1.0),
't': (0.0, inf)},
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'extra_fields': None}
We see three properties (key) in this dictionary, of which two are essential:
- The
loglikfield, which points to the likelihood function - The
backendfield, which can be eitherNone(defaulting to pytensor foranalyticallikelihoods),jaxorpytensor - The
boundsfield, which specifies bounds on a subset of the model parameters - The
default_priorsfield, which specifies parameter wise priors
If you provide bounds for a parameter, but no default_priors, a Uniform prior that respects the specified bounds will be applied.
Next, let's look at the approx_differentiable part.
The likelihood in this part is based on a LAN which was available in HDDM through the LAN extension.
hssm.config.default_model_config["ddm"]["likelihoods"]["approx_differentiable"]
{'loglik': 'ddm.onnx',
'backend': 'jax',
'default_priors': {'t': {'name': 'HalfNormal', 'sigma': 2.0}},
'bounds': {'v': (-3.0, 3.0),
'a': (0.3, 2.5),
'z': (0.0, 1.0),
't': (0.0, 2.0)},
'extra_fields': None}
We see that the loglik field is now a string that points to a .onnx file.
Onnx is a meta framework for Neural Network specification, that allows translation between deep learning Frameworks. This is the preferred format for the neural networks we store in our model reservoir on HuggingFace.
Moreover notice that we now have a backend field. We allow for two primary backends in the approx_differentiable field.
pytensorjax
The jax backend assumes that your likelihood is described as a jax function, the pytensor backend assumes that your likelihood is described as a pytensor function. Ok not that surprising...
We won't dwell on this here, however the key idea is to provide users with a large degree of flexibility in describing their likelihood functions and moreover to allow targeted optimization towards MCMC sampler types that PyMC allows us to access.
You can find a dedicated tutorial in the documentation, which describes the different likelihoods in much more detail.
Instead, let's take a quick look at how these newfound insights can be used for custom model definition.
hssm_alternative_model = hssm.HSSM(
data=dataset,
model="ddm",
loglik_kind="approx_differentiable",
)
Model initialized successfully.
hssm_alternative_model.loglik_kind
'approx_differentiable'
In this case we actually built the model class with an approx_differentiable LAN likelihood, instead of the default analytical likelihood we used in the beginning of the tutorial. The assumed generative model remains the ddm however!
hssm_alternative_model.sample(
sampler="pymc",
cores=1,
chains=2,
draws=1000,
tune=1000,
idata_kwargs=dict(
log_likelihood=False
), # model comparison metrics usually need this!
mp_ctx="spawn",
)
Using default initvals.
Initializing NUTS using adapt_diag... Sequential sampling (2 chains in 1 job) NUTS: [t, a, z, v]
Output()
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 63 seconds. We recommend running at least 4 chains for robust computation of convergence diagnostics
-
<xarray.Dataset> Size: 72kB Dimensions: (chain: 2, draw: 1000) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: v (chain, draw) float64 16kB 0.5368 0.5377 0.5226 ... 0.5525 0.5804 a (chain, draw) float64 16kB 1.481 1.437 1.512 ... 1.432 1.441 1.491 z (chain, draw) float64 16kB 0.4624 0.4922 0.4705 ... 0.508 0.4946 t (chain, draw) float64 16kB 0.4729 0.5499 0.4761 ... 0.5121 0.5558 Attributes: created_at: 2025-09-29T20:10:00.510764+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 63.46027493476868 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 268kB Dimensions: (chain: 2, draw: 1000) Coordinates: * chain (chain) int64 16B 0 1 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) energy (chain, draw) float64 16kB 1.03e+03 ... 1.034e+03 step_size_bar (chain, draw) float64 16kB 0.6152 0.6152 ... 0.661 divergences (chain, draw) int64 16kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 perf_counter_start (chain, draw) float64 16kB 1.668e+06 ... 1.668e+06 diverging (chain, draw) bool 2kB False False ... False False step_size (chain, draw) float64 16kB 0.5823 0.5823 ... 0.8641 ... ... acceptance_rate (chain, draw) float64 16kB 1.0 0.8801 ... 0.6555 lp (chain, draw) float64 16kB -1.027e+03 ... -1.032e+03 reached_max_treedepth (chain, draw) bool 2kB False False ... False False perf_counter_diff (chain, draw) float64 16kB 0.006734 ... 0.007361 index_in_trajectory (chain, draw) int64 16kB 1 -3 -4 2 -2 ... -2 3 3 -1 max_energy_error (chain, draw) float64 16kB -0.4834 0.2833 ... 0.5488 Attributes: created_at: 2025-09-29T20:10:00.527562+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 63.46027493476868 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.15.0 -
<xarray.Dataset> Size: 12kB Dimensions: (__obs__: 500, rt,response_extra_dim_0: 2) Coordinates: * __obs__ (__obs__) int64 4kB 0 1 2 3 4 ... 496 497 498 499 * rt,response_extra_dim_0 (rt,response_extra_dim_0) int64 16B 0 1 Data variables: rt,response (__obs__, rt,response_extra_dim_0) float64 8kB 1... Attributes: created_at: 2025-09-29T20:10:00.531110+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 modeling_interface: bambi modeling_interface_version: 0.15.0
az.plot_forest(hssm_alternative_model.traces)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

We can take this further and specify a completely custom likelihood. See the dedicated tutorial for more examples!
We will see one specific example below to illustrate another type of likelihood function we have available for model building in HSSM, the Blackbox likelihood.
'Blackbox' Likelihoods¶

What is a Blackbox Likelihood Function?¶
A Blackbox Likelihood Function is essentially any Python callable (function) that provides trial by trial likelihoods for your model of interest. What kind of computations are performed in this Python function is completely arbitrary.
E.g. you could built a function that performs forward simulation from you model, constructs are kernel-density estimate for the resulting likelihood functions and evaluates your datapoints on this ad-hoc generated approximate likelihood.
What I just described is a once state-of-the-art method of performing simulation based inference on Sequential Sampling models, a precursor to LANs if you will.
We will do something simpler to keep it short and sweet, but really... the possibilities are endless!

Simulating simple dataset from the DDM¶
As always, let's begin by generating some simple dataset.
# Set parameters
param_dict_blackbox = dict(v=0.5, a=1.5, z=0.5, t=0.5)
# Simulate
dataset_blackbox = hssm.simulate_data(model="ddm", theta=param_dict_blackbox, size=1000)
Define the likelihood¶
Now the fun part... we simply define a Python function my_blackbox_loglik which takes in our data as well as a bunch of model parameters (in our case the familiar v,a, z, t from the DDM).
The function then does some arbitrary computation inside (in our case e.g. we pass the data and parameters to the DDM log-likelihood from our predecessor package HDDM).
The important part is that inside my_blackbox_loglik anything can happen. We happen to call a little custom function that defines the likelihood of a DDM.
Fun fact: It is de-facto the likelihood which is called by HDDM.
def my_blackbox_loglik(data, v, a, z, t, err=1e-8):
"""Create a custom blackbox likelihood function."""
data = data[:, 0] * data[:, 1]
data_nrows = data.shape[0]
# Our function expects inputs as float64, but they are not guaranteed to
# come in as such --> we type convert
return hddm_wfpt.wfpt.wiener_logp_array(
np.float64(data),
(np.ones(data_nrows) * v).astype(np.float64),
np.ones(data_nrows) * 0,
(np.ones(data_nrows) * 2 * a).astype(np.float64),
(np.ones(data_nrows) * z).astype(np.float64),
np.ones(data_nrows) * 0,
(np.ones(data_nrows) * t).astype(np.float64),
np.ones(data_nrows) * 0,
err,
1,
)
Define HSSM class with our Blackbox Likelihood¶
We can now define our HSSM model class as usual, however passing our my_blackbox_loglik() function to the loglik argument, and passing as loglik_kind = blackbox.
The rest of the model config is as usual. Here we can reuse our ddm model config, and simply specify bounds on the parameters (e.g. your Blackbox Likelihood might be trustworthy only on a restricted parameters space).
blackbox_model = hssm.HSSM(
data=dataset_blackbox,
model="ddm",
loglik=my_blackbox_loglik,
loglik_kind="blackbox",
model_config={
"bounds": {
"v": (-10.0, 10.0),
"a": (0.5, 5.0),
"z": (0.0, 1.0),
}
},
t=bmb.Prior("Uniform", lower=0.0, upper=2.0),
)
Model initialized successfully.
blackbox_model.graph()
max_shape: (1000,) size: (np.int64(1000),)

sample = blackbox_model.sample()
Using default initvals.
Multiprocess sampling (4 chains in 4 jobs) CompoundStep >Slice: [t] >Slice: [a] >Slice: [z] >Slice: [v]
Output()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 26 seconds. 100%|██████████| 4000/4000 [00:01<00:00, 2078.36it/s]
NOTE:
Since Blackbox likelihood functions are assumed to not be differentiable, our default sampler for such likelihood functions is a Slice sampler. HSSM allows you to choose any other suitable sampler from the PyMC package instead. A bunch of options are available for gradient-free samplers.
Results¶
az.summary(sample)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| z | 0.473 | 0.013 | 0.446 | 0.496 | 0.000 | 0.000 | 1204.0 | 1738.0 | 1.0 |
| v | 0.596 | 0.034 | 0.531 | 0.658 | 0.001 | 0.001 | 1369.0 | 2017.0 | 1.0 |
| t | 0.472 | 0.024 | 0.428 | 0.516 | 0.001 | 0.000 | 1280.0 | 1797.0 | 1.0 |
| a | 1.536 | 0.029 | 1.480 | 1.590 | 0.001 | 0.000 | 1499.0 | 1827.0 | 1.0 |
az.plot_trace(
sample,
lines=[(key_, {}, param_dict_blackbox[key_]) for key_ in param_dict_blackbox],
)
plt.tight_layout()

HSSM Random Variables in PyMC¶
We covered a lot of ground in this tutorial so far. You are now a sophisticated HSSM user.
It is therefore time to reveal a secret. We can actuallly peel back one more layer...

Instead of letting HSSM help you build the entire model, we can instead use HSSM to construct valid PyMC distributions and then proceed to build a custom PyMC model by ourselves...

We will illustrate the simplest example below. It sets a pattern that can be exploited for much more complicated modeling exercises, which importantly go far beyond what our basic HSSM class may facilitate for you!
See the dedicated tutorial in the documentation if you are interested.
Let's start by importing a few convenience functions:
# DDM models (the Wiener First-Passage Time distribution)
from hssm.distribution_utils import make_distribution
from hssm.likelihoods import DDM
Simulate some data¶
# Simulate
param_dict_pymc = dict(v=0.5, a=1.5, z=0.5, t=0.5)
dataset_pymc = hssm.simulate_data(model="ddm", theta=param_dict_pymc, size=1000)
Build a custom PyMC Model¶
We can now use our custom random variable DDM directly in a PyMC model.
import pymc as pm
with pm.Model() as ddm_pymc:
v = pm.Uniform("v", lower=-10.0, upper=10.0)
a = pm.HalfNormal("a", sigma=2.0)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
ddm = DDM(
"DDM", observed=dataset_pymc[["rt", "response"]].values, v=v, a=a, z=z, t=t,
)
Let's check the model graph:
pm.model_to_graphviz(model=ddm_pymc)
size all scalar: (np.int64(1000),)

Looks remarkably close to our HSSM version!
We can use PyMC directly to sample and finally return to ArviZ for some plotting!
with ddm_pymc:
ddm_pymc_trace = pm.sample()
Initializing NUTS using jitter+adapt_diag... Multiprocess sampling (4 chains in 4 jobs) NUTS: [v, a, z, t]
Output()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 17 seconds.
az.plot_trace(
ddm_pymc_trace,
lines=[(key_, {}, param_dict_pymc[key_]) for key_ in param_dict_pymc],
)
plt.tight_layout()

az.plot_forest(ddm_pymc_trace)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

Alternative Models with PyMC¶
With very little extra work, we can in fact load any of the models accessible via HSSM. Here is an example, where we load the angle model instead.
We first construction the likelihood function, using make_likelihood_callable().
Then we produce a valid pymc.distribution using the
make_distribution() utility function.
Just like the DDM class above, we can then use this distribution inside a PyMC model.
from hssm.distribution_utils import make_likelihood_callable
angle_loglik = make_likelihood_callable(
loglik="angle.onnx",
loglik_kind="approx_differentiable",
backend="jax",
params_is_reg=[0, 0, 0, 0, 0],
)
ANGLE = make_distribution(
"angle",
loglik=angle_loglik,
list_params=hssm.defaults.default_model_config["angle"]["list_params"],
)
Note that we need to supply the params_is_reg argument ("reg" for "regression").
This is a boolean vector, which specifies for each input to the likelihood function, whether or not it is defined to be "trial-wise", as is expected if the parameter
is the output e.g. of a regression function.
import pymc as pm
# Angle pymc
with pm.Model() as angle_pymc:
# Define parameters
v = pm.Uniform("v", lower=-10.0, upper=10.0)
a = pm.Uniform("a", lower=0.5, upper=2.5)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
theta = pm.Uniform("theta", lower=-0.1, upper=1.0)
# Our RV
angle = ANGLE(
"ANGLE",
v=v,
a=a,
z=z,
t=t,
theta=theta,
observed=dataset_pymc[["rt", "response"]].values,
)
with angle_pymc:
idata_object = pm.sample(nuts_sampler="numpyro")
sample: 100%|██████████| 2000/2000 [00:15<00:00, 131.79it/s, 7 steps of size 3.93e-01. acc. prob=0.89] sample: 100%|██████████| 2000/2000 [00:15<00:00, 125.09it/s, 7 steps of size 3.35e-01. acc. prob=0.92] sample: 100%|██████████| 2000/2000 [00:16<00:00, 123.72it/s, 7 steps of size 3.25e-01. acc. prob=0.93] sample: 100%|██████████| 2000/2000 [00:17<00:00, 116.59it/s, 7 steps of size 2.88e-01. acc. prob=0.93]
az.plot_trace(
idata_object, lines=[(key_, {}, param_dict_pymc[key_]) for key_ in param_dict_pymc]
)
plt.tight_layout()

Regression via PyMC¶
Finally to illustrate the usage of PyMC a little more elaborately, let us build a PyMC model with regression components.
from typing import Optional
def make_params_is_reg_vec(
reg_parameters: Optional[list] = None, parameter_names: Optional[list] = None
):
"""Make a list of Trues and Falses to indicate which parameters are vectors."""
if (not isinstance(reg_parameters, list)) or (
not isinstance(parameter_names, list)
):
raise ValueError("Both reg_parameters and parameter_names should be lists")
bool_list = [0] * len(parameter_names)
for param in reg_parameters:
bool_list[parameter_names.index(param)] = 1
return bool_list
# Set up trial by trial parameters
v_intercept_pymc_reg = 0.3
x_pymc_reg = np.random.uniform(-1, 1, size=1000)
v_x_pymc_reg = 0.8
y_pymc_reg = np.random.uniform(-1, 1, size=1000)
v_y_pymc_reg = 0.3
v_pymc_reg = v_intercept + (v_x * x) + (v_y * y)
param_dict_pymc_reg = dict(
v_Intercept=v_intercept_pymc_reg,
v_x=v_x_pymc_reg,
v_y=v_y_pymc_reg,
v=v_pymc_reg,
a=1.5,
z=0.5,
t=0.1,
theta=0.0,
)
# base dataset
pymc_reg_data = hssm.simulate_data(model="ddm", theta=param_dict_pymc_reg, size=1)
# Adding covariates into the datsaframe
pymc_reg_data["x"] = x
pymc_reg_data["y"] = y
# Make the boolean vector for params_is_reg argument
bool_param_reg = make_params_is_reg_vec(
reg_parameters=["v"],
parameter_names=hssm.defaults.default_model_config["angle"]["list_params"],
)
angle_loglik = make_likelihood_callable(
loglik="angle.onnx",
loglik_kind="approx_differentiable",
backend="jax",
params_is_reg=bool_param_reg,
)
ANGLE = make_distribution(
"angle",
loglik=angle_loglik,
list_params=hssm.defaults.default_model_config["angle"]["list_params"],
)
import pytensor.tensor as pt
with pm.Model(
coords={
"idx": pymc_reg_data.index,
"resp": ["rt", "response"],
"features": ["x", "y"],
}
) as pymc_model_reg:
# Features
x_ = pm.Data("x", pymc_reg_data["x"].values, dims="idx")
y_ = pm.Data("y", pymc_reg_data["y"].values, dims="idx")
# Target
obs = pm.Data("obs", pymc_reg_data[["rt", "response"]].values, dims=("idx", "resp"))
# Priors
a = pm.Uniform("a", lower=0.5, upper=2.5)
z = pm.Uniform("z", lower=0.01, upper=0.99)
t = pm.Uniform("t", lower=0.0, upper=0.6)
theta = pm.Uniform("theta", lower=-0.1, upper=1.0)
v_Intercept = pm.Uniform("v_Intercept", lower=-3, upper=3)
v_betas = pm.Normal("v_beta", mu=[0, 0], sigma=0.5, dims=("features"))
# Regression equation
v = pm.Deterministic(
"v", v_Intercept + pt.stack([x_, y_], axis=1) @ v_betas, dims="idx"
)
# Our RV
angle = ANGLE(
"angle",
v=v.squeeze(),
a=a,
z=z,
t=t,
theta=theta,
observed=obs,
dims=("idx", "resp"),
)
with pymc_model_reg:
idata_pymc_reg = pm.sample(
nuts_sampler="numpyro", idata_kwargs={"log_likelihood": True}
)
sample: 100%|██████████| 2000/2000 [00:13<00:00, 150.54it/s, 31 steps of size 1.84e-01. acc. prob=0.95] sample: 100%|██████████| 2000/2000 [00:09<00:00, 204.08it/s, 7 steps of size 3.12e-01. acc. prob=0.87] sample: 100%|██████████| 2000/2000 [00:10<00:00, 199.93it/s, 15 steps of size 2.98e-01. acc. prob=0.88] sample: 100%|██████████| 2000/2000 [00:11<00:00, 167.67it/s, 7 steps of size 2.35e-01. acc. prob=0.91]
az.plot_forest(idata_pymc_reg, var_names=["~v"])
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)

All layers peeled back, the only limit in your modeling endeavors becomes the limit of the PyMC universe!
